
Clouded Judgement 3.26.26 - Per Token Pricing

Every week I’ll provide updates on the latest trends in cloud software companies. Follow along to stay up to date!
From GPU Hours to Token Dollars
One thing I’m starting to believe - the companies who figure out pricing and packaging the fastest will have a big edge in the early days of this AI phase shift. I think it’s one of the hardest problems right now for any AI company! What makes pricing so difficult in an entirely new (and expensive) line item has entered COGS - inference. Whether you’re paying OpenAI / Anthropic directly, or paying someone else to run open source models, inference costs are exploding (and we’re just getting started….). A big question becomes - how can you price your product such that you don’t torpedo your business into perpetual negative gross margin land (or said more positively, how can you price your product to more tightly align with value delivered).
A couple weeks ago I wrote a post titled “Get in the Token Path” which described one way to better align pricing models (and a way I think will ultimately lead to the most success). I think it’s so important to figure out pricing because we’re entering a world where your pricing model is your business model. In traditional SaaS, pricing was important but also forgiving. You had 80%+ gross margins, so even if your packaging wasn’t perfect, there was a huge cushion. You could underprice a seat, overprovision features, give away usage for free and it didn’t matter because the incremental cost of serving another user was basically zero. That’s not the case anymore. When every agent action, every “magic” feature triggers real inference costs on the backend, the gap between your pricing model and your cost structure becomes existential. Price too low and you’re literally paying customers to use your product. Price too high and you lose to the competitor who figured it out first. And the costs themselves are a moving target. Token prices are falling fast, hardware efficiency improves every generation, and the mix of models you’re calling changes the math entirely. You can’t just set a $50/seat/month price and forget it.
But here’s the flip side (and I think this is underappreciated). The companies that do get pricing right have a chance to capture way more value per customer than was ever possible in the old SaaS world. If you can tightly align price with value delivered, charging more when your product does more, scaling with outcomes rather than headcount th,e ceiling on what you can extract per customer goes way, way up. A traditional SaaS company selling seats was always capped by “how many humans work at this company.” An AI-native company selling on usage, outcomes, or work completed? The TAM within each account is theoretically limitless. Getting pricing wrong is fatal. But getting it right is a superpower.
So back to pricing…I think we’re about to see an explosion of pricing models based on pricing per token. It may not literally be “per token” - I think we’ll see a lot of credit based pricing structures emerge where on the back end credits buy you tokens in a somewhat obfuscated way. More multi product companies are coming out, and companies are layering on additional products faster and faster than ever before. Pricing and packaging for multi-product companies is really hard (you want to capture value for incremental products delivered). But most of these will all have token generation as a commonality, and I think we’ll see a lot of credit based pricing models emerge where credits basically buy you a certain amount of consumption across any of the products offered.
Related to all of this - I think we’re also about to go through a shift in how GPUs are monetized as the world moves from a training heavy one to an inference heavy one. For the last decade, the world has rented GPUs by the hour. You go to AWS, CoreWeave, Lambda, whoever - and you pay something like $2-4 per GPU hour. That’s it. That’s the business model. You’re basically renting a very expensive piece of silicon by the clock, the same way you’d rent a U-Haul truck. Doesn’t matter if you’re driving it across the country fully loaded or it’s sitting in your driveway. You’re paying by the hour.
This model made sense for training. Training is a big batch job and more of a cost center - you spin up a cluster, you run the job for days or weeks, and you’re done. There isn’t really direct “revenue” tied to this cost (obviously there is as you start charging for model access, but the direct cost of training isn’t paired with revenue). Hourly rental works fine. But we’re not in a training-dominated world anymore. We’re rapidly shifting into an inference-dominated world, and that changes everything about how these GPUs should get priced.
Jensen Huang spent a huge chunk of his GTC keynote this month hammering this point home. He showed what he called a “Pareto frontier” - basically a chart that maps the tradeoff between throughput (how many total tokens you can pump out) and latency (how fast each individual user gets their response). The key insight is that depending on where you sit on that curve, the economic value of a GPU hour changes dramatically.
Let me make this concrete with some illustrative figures. Today, if you’re a GPU cloud provider, you’re renting out an H100 for roughly $2-4/hour (it can range more than that depending on what type of GPU with what specs, whether you’re buying on demand or on a committed deal, etc). That's your revenue per GPU hour. That's what the market pays. But now think about it from the other direction. A single GPU in the GB300 NVL72 generates roughly 15,000 tokens per second. The full rack — 72 GPUs working together — pushes that to over 1 million tokens per second, or roughly 4 billion tokens per hour. Now, renting that equivalent GPU capacity by the hour might run you $150-300/hour (72 GPUs at $2-4 each). But price those tokens instead. Even at rock-bottom commodity rates of $0.15-0.20 per million output tokens, 4 billion tokens generates $600-800/hour in token revenue — easily 2-4x the hourly rental value. And that's at the cheapest prices on the market. Mid-tier models charge $8-15 per million output tokens, which would push the math into the thousands per hour. The simple logic: a GPU rented by the hour is priced based on the cost of the silicon. A GPU monetized by the token is priced based on the value of the output. And it turns out the output is worth a lot more than the silicon.
Same GPU. Same hour. But when you price the output in tokens instead of clock time, the monetization more than doubles.
This is where Jensen’s Pareto chart becomes so powerful. On one end of the curve, you’re running maximum throughput - serving tons of users, batch workloads, cheap tokens. On the other end, you’re running low latency - fast, responsive, premium tokens for things like real-time agents. The further you push toward the premium end, the more revenue you extract per GPU hour. And with each generation of hardware pushing that Pareto frontier outward, the gap between “what you charge per hour” and “what you could charge per token” keeps getting wider.
So why does this matter for founders?
First, if you’re building on top of inference, you need to understand that the cost of tokens is going to keep falling (and fast). Every hardware generation pushes the frontier out further. NVIDIA’s own numbers show Vera Rubin delivering 5x the inference throughput of Blackwell, with token costs falling 10x. That’s deflationary pressure that will compound relentlessly. If your business model depends on tokens being expensive, you’re on the wrong side of this curve.
Second, and this is the more interesting part in my opinion. For the companies actually running the GPUs, this shift from hourly rental to token-based pricing is transformational. It turns GPUs from depreciating assets into revenue-generating factories. Under the old model, you buy a GPU, you rent it out by the hour, and you’re in a race against depreciation. The next chip comes out, your hourly rate drops, and you’re chasing a declining price (interestingly, H100 prices have actually been rising as the market remains so incredibly supply constrained). It’s a cost center. You’re basically a landlord watching your property value fall every 18 months.
Under the token model, the equation flips. You’re now selling output vs raw compute time. A token that helps an agent close a sales deal is worth a lot more than a token that summarizes a Wikipedia page, even though they cost roughly the same to generate. That’s the whole point of Jensen’s tiered token pricing vision - different points on the Pareto curve command different price points.
This is one reason why the Groq acquisition is so interesting. The Groq LPU is purpose-built for inference - ultra-low latency token generation. By integrating Groq into NVIDIA’s ecosystem (alongside their Dynamo inference orchestration software), they’re essentially building out the full stack to help GPU operators maximize token revenue, not just clock-time rental revenue. It extends the business model for everyone in the chain.
Think about the analogy to cloud computing. In the early days of AWS, you rented VMs by the hour. Then Lambda came along and you paid per function invocation. Then you started paying per API call, per request, per transaction. The pricing got more granular and more aligned with actual value delivered. The same thing is happening with GPUs. We’re moving from “pay per hour of silicon” to “pay per unit of intelligence produced.” And just like in cloud, the companies that figure out how to price on value (not just cost) will capture disproportionate economics.
One more thing. This shift has massive implications for the AI model providers too - the OpenAIs and Anthropics of the world. If you’re sitting on top of billions of dollars of GPU infrastructure and you’re selling tokens through APIs, you want to be on the high end of that Pareto curve. You want premium, low-latency, high-quality tokens that you can charge $10-15 per million output tokens for (not commodity batch tokens at $0.10). The model providers who can deliver the most valuable tokens (through better reasoning, faster responses, or more reliable agents) will extract the most revenue per GPU hour from their infrastructure. This is actually what’s going to drive these companies to profitability - not just scale (which will help!), but token monetization efficiency.
The world is moving from GPU hours to token dollars. For founders building in this ecosystem, the takeaway is this: understand where you sit on the Pareto curve, because that’s what determines your economics. Are you building for throughput (cheap, high-volume tokens)? Or for latency (premium, real-time tokens)? The hardware is getting better at both, but the pricing power lives at the premium end. And the companies that figure out how to monetize tokens based on value (not just pass through the cost of compute) are the ones that will have a big advantage.
And this is where the credit-based pricing model I mentioned earlier becomes so interesting. Credits give you a flexible abstraction layer that lets you sit on top of all of this complexity without exposing it directly to the customer. Token costs are falling, model mix is shifting, you’re running five different models at five different price points on the backend. The customer doesn’t need to know any of that. They buy credits, credits buy them outcomes across your product suite, and you manage the token economics underneath. It’s the same playbook the cloud providers eventually landed on (committed spend across a broad set of services), and I think it’s where the best AI-native companies will land too. The ones who figure out that abstraction, pricing on value and managing token costs as an internal optimization problem rather than a customer-facing one, will build the most durable businesses of this next era.
I had a fun time putting this post together! I’d love to speak with experts in the AI pricing and packaging space. Maybe even host a town hall with people who want to learn about pricing and packaging in the age of AI. Hit me up if you’d like to participate!
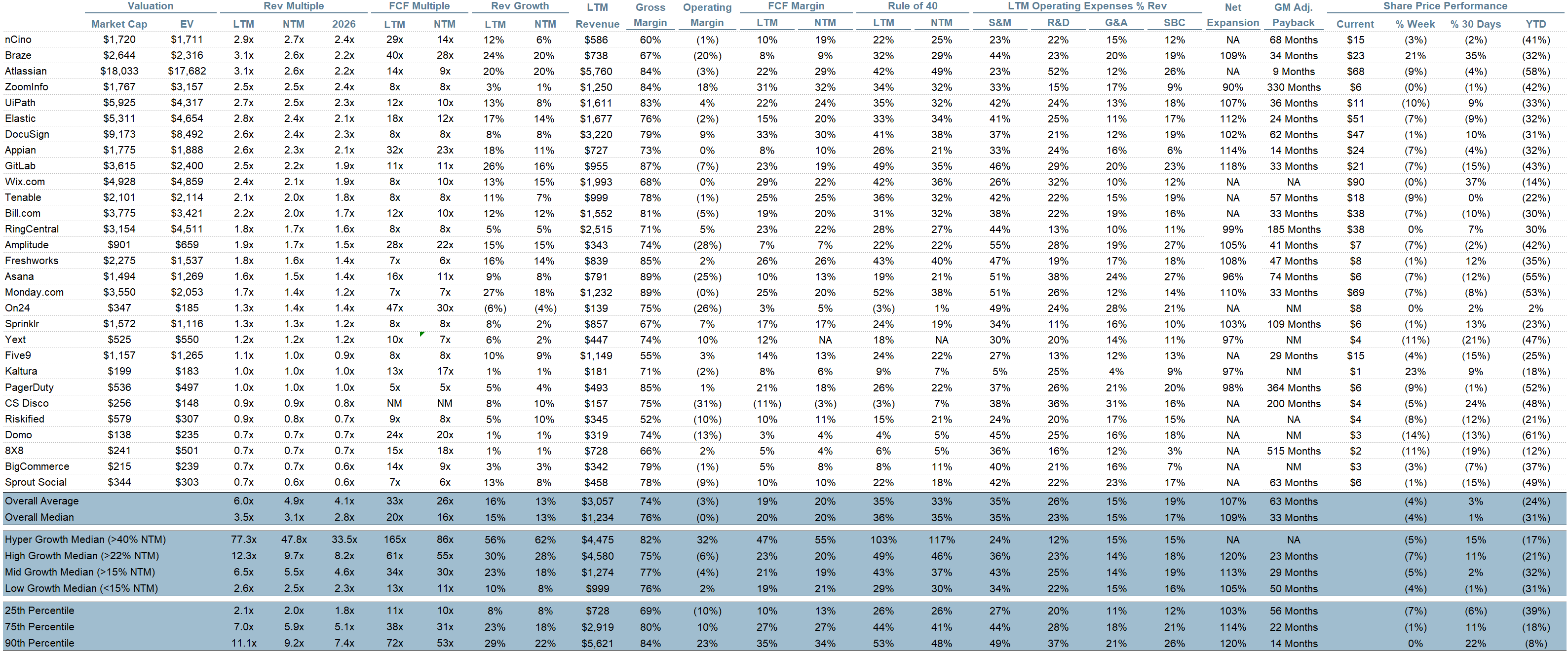
Quarterly Reports Summary

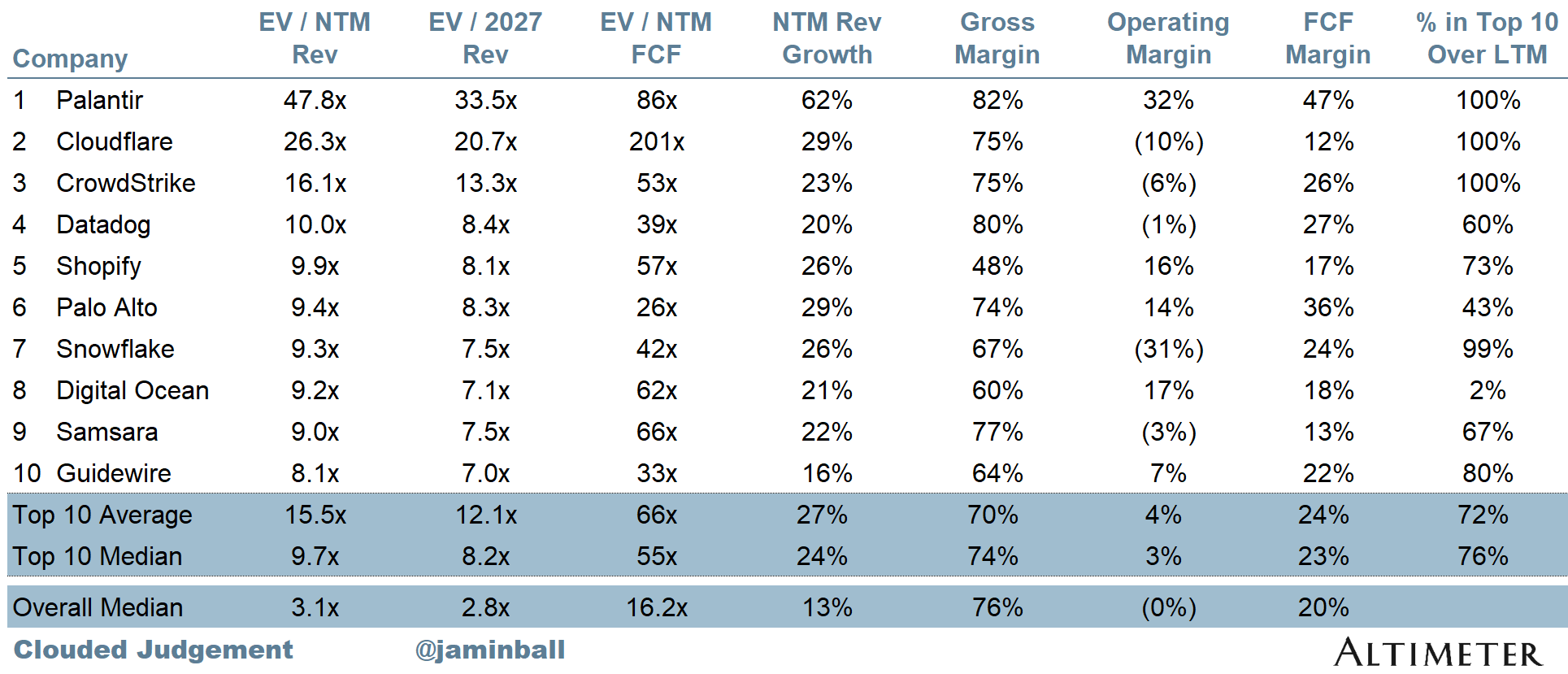
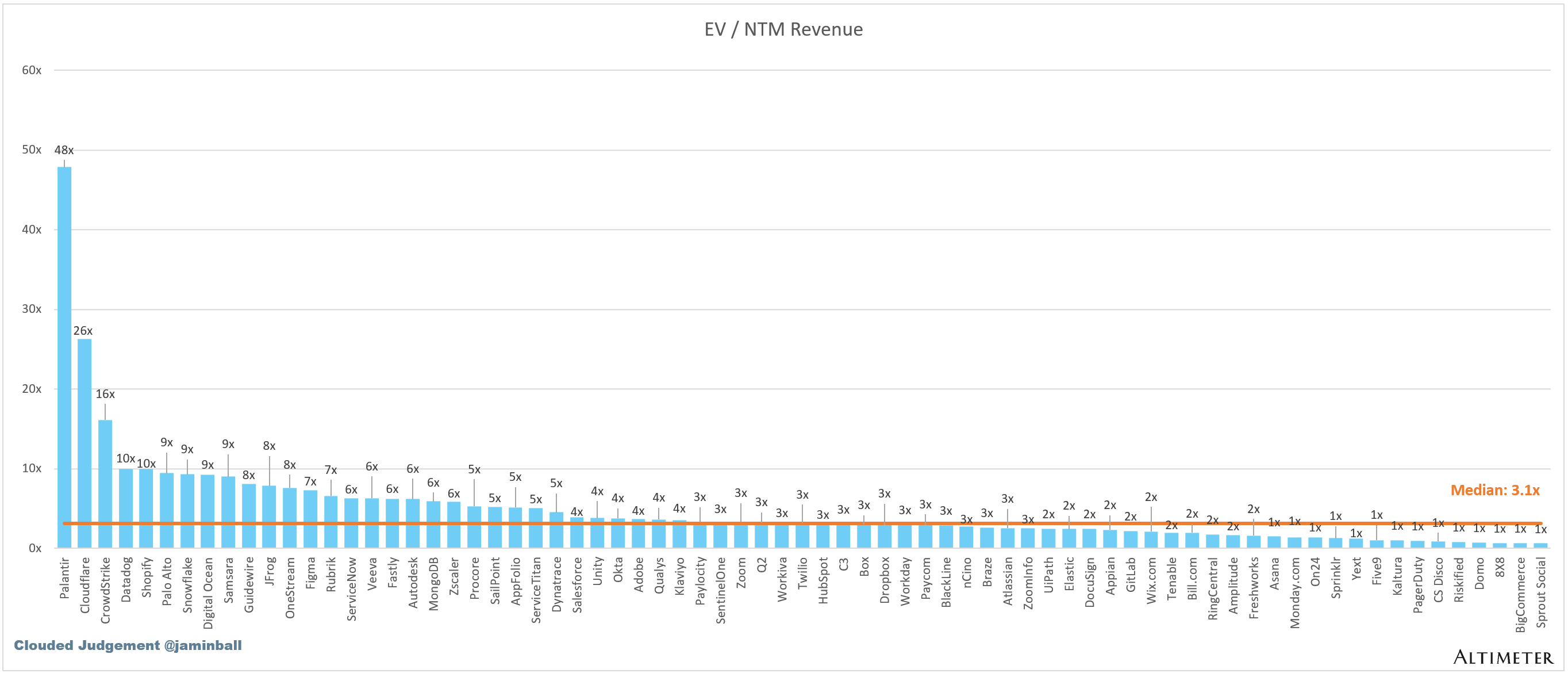
Top 10 EV / NTM Revenue Multiples
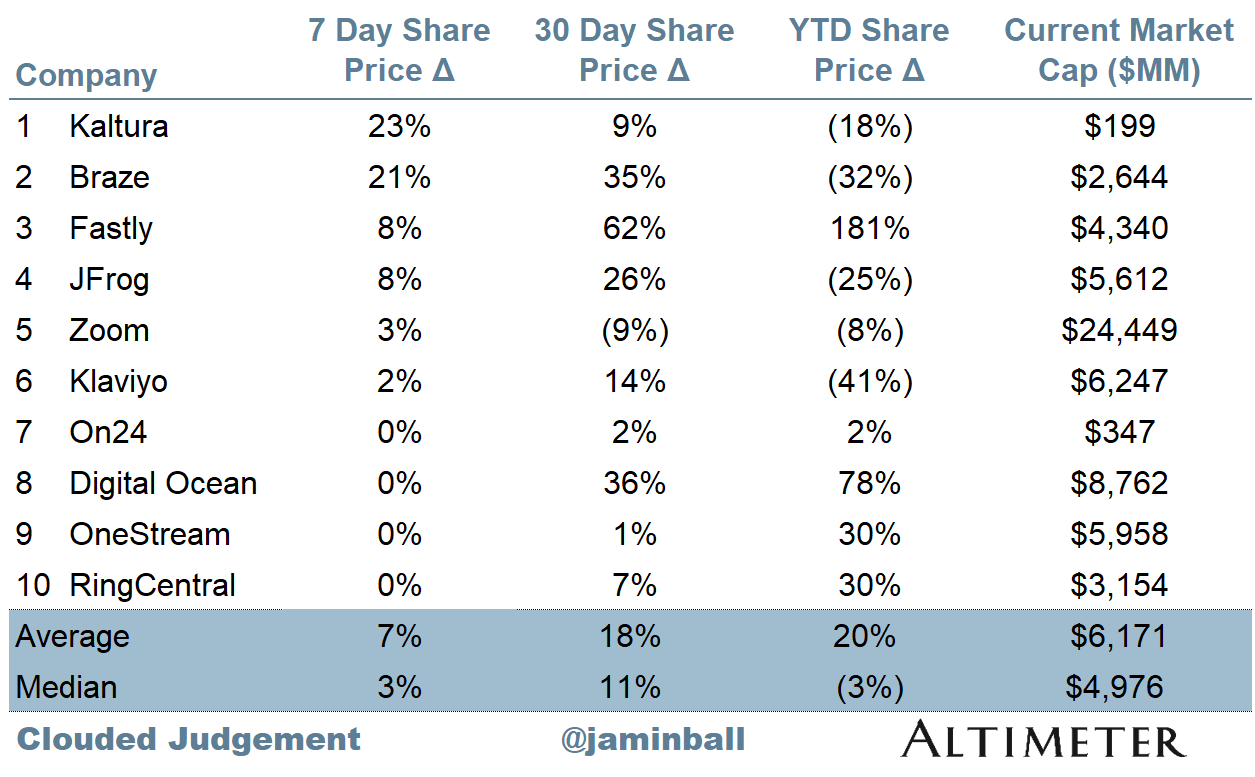
Top 10 Weekly Share Price Movement
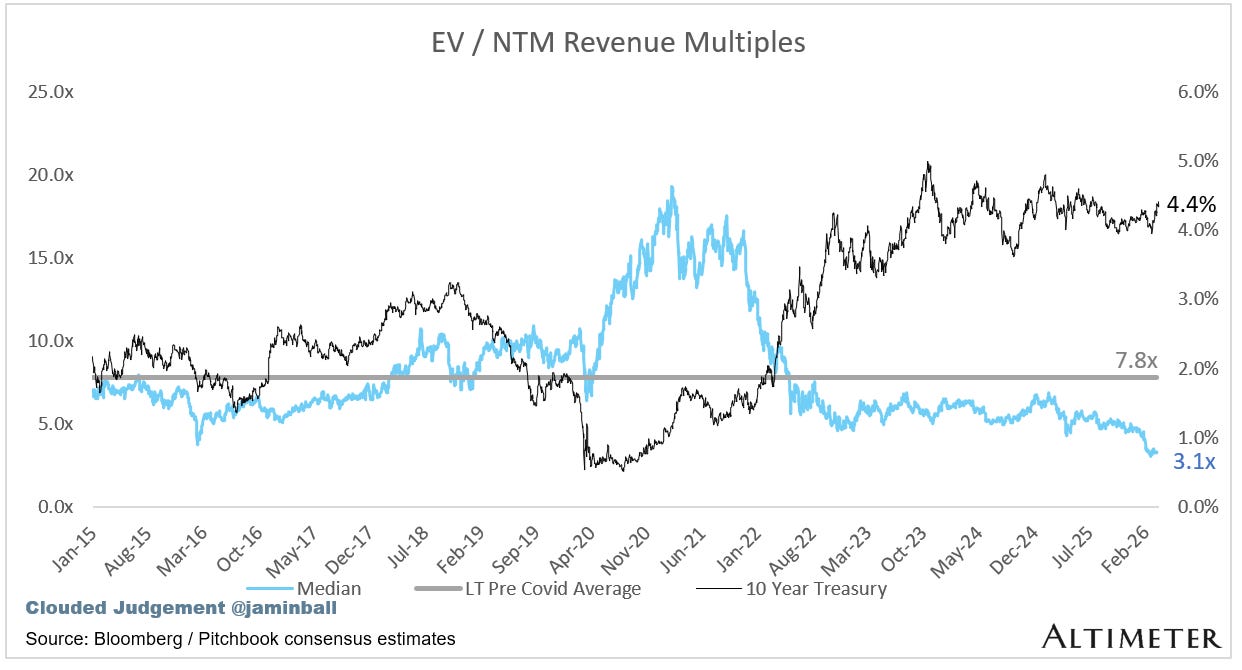
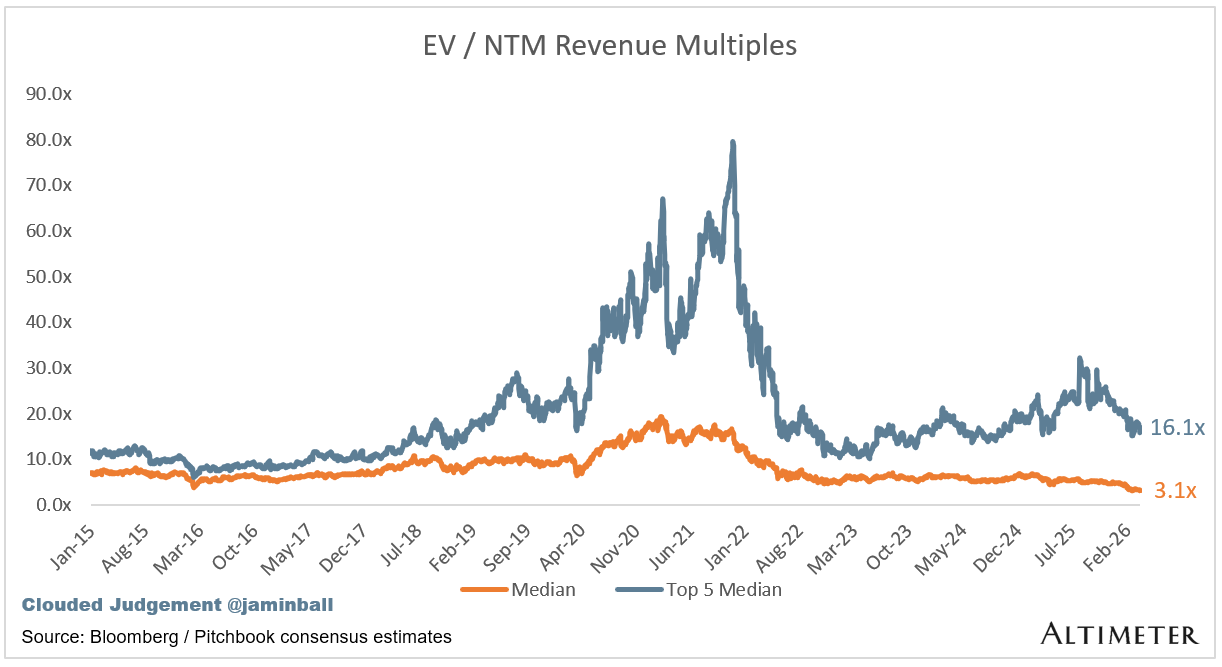
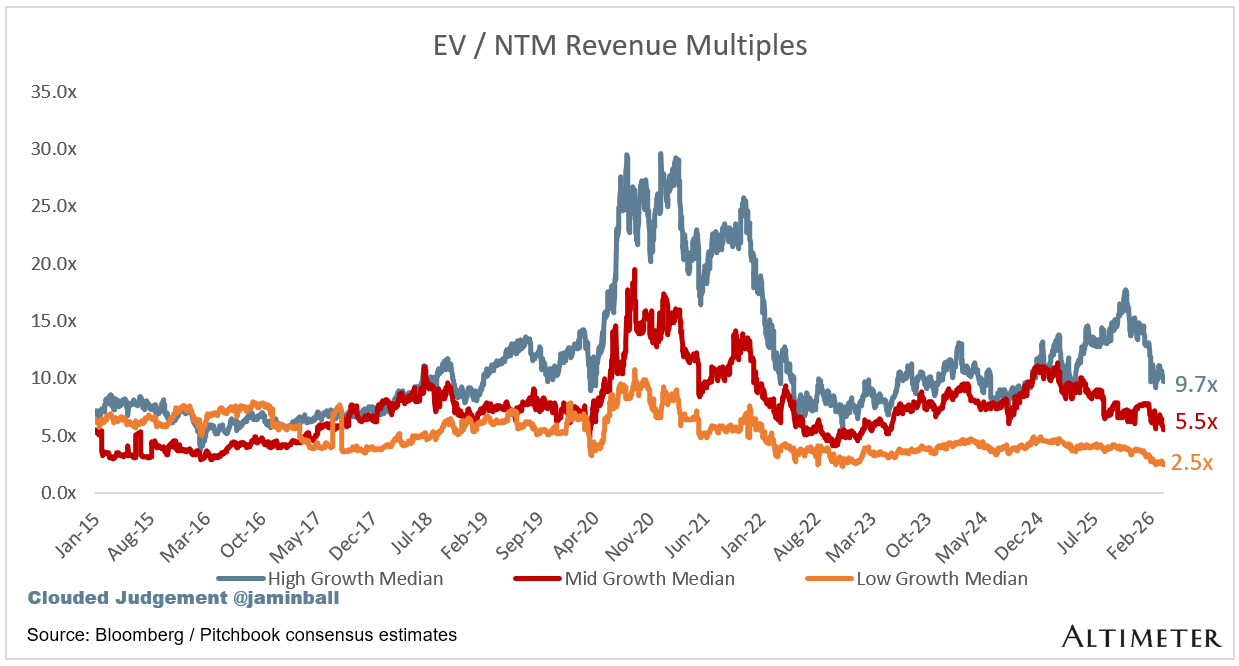
Update on Multiples
SaaS businesses are generally valued on a multiple of their revenue - in most cases the projected revenue for the next 12 months. Revenue multiples are a shorthand valuation framework. Given most software companies are not profitable, or not generating meaningful FCF, it’s the only metric to compare the entire industry against. Even a DCF is riddled with long term assumptions. The promise of SaaS is that growth in the early years leads to profits in the mature years. Multiples shown below are calculated by taking the Enterprise Value (market cap + debt - cash) / NTM revenue.
Overall Stats:
Overall Median: 3.1x
Top 5 Median: 16.1x
10Y: 4.4%
Bucketed by Growth. In the buckets below I consider high growth >22% projected NTM growth, mid growth 15%-22% and low growth <15%. I had to adjusted the cut off for “high growth.” If 22% feels a bit arbitrary, it’s because it is…I just picked a cutoff where there were ~10 companies that fit into the high growth bucket so the sample size was more statistically significant
High Growth Median: 9.7x
Mid Growth Median: 5.5x
Low Growth Median: 2.5x
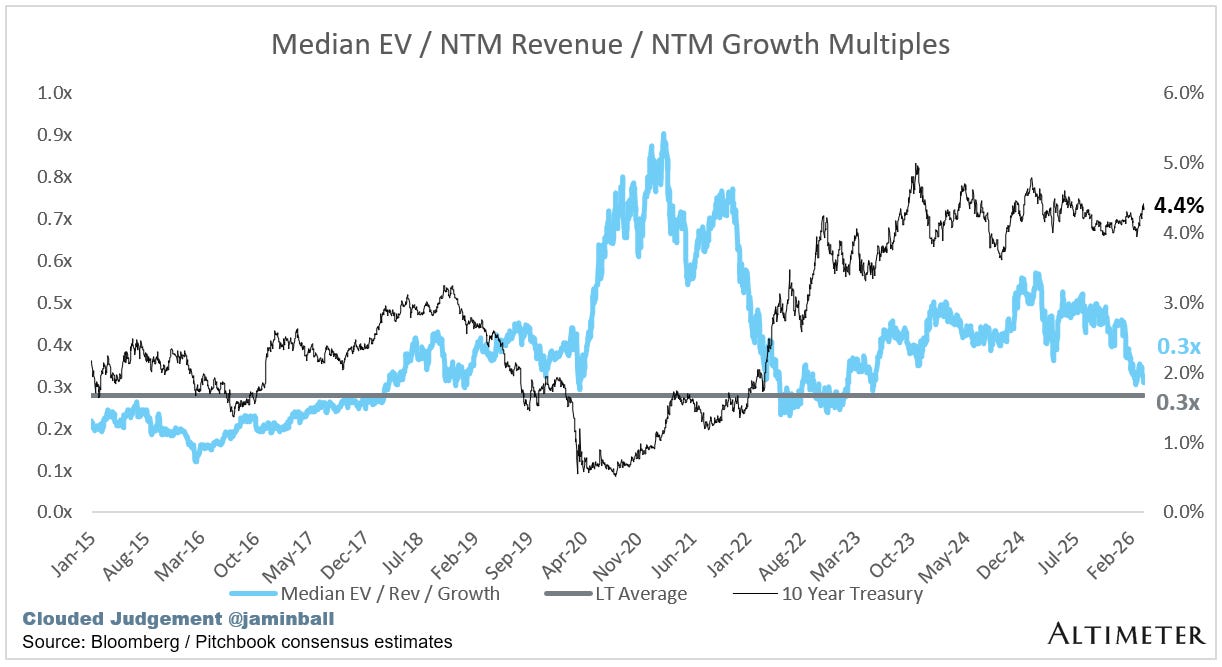
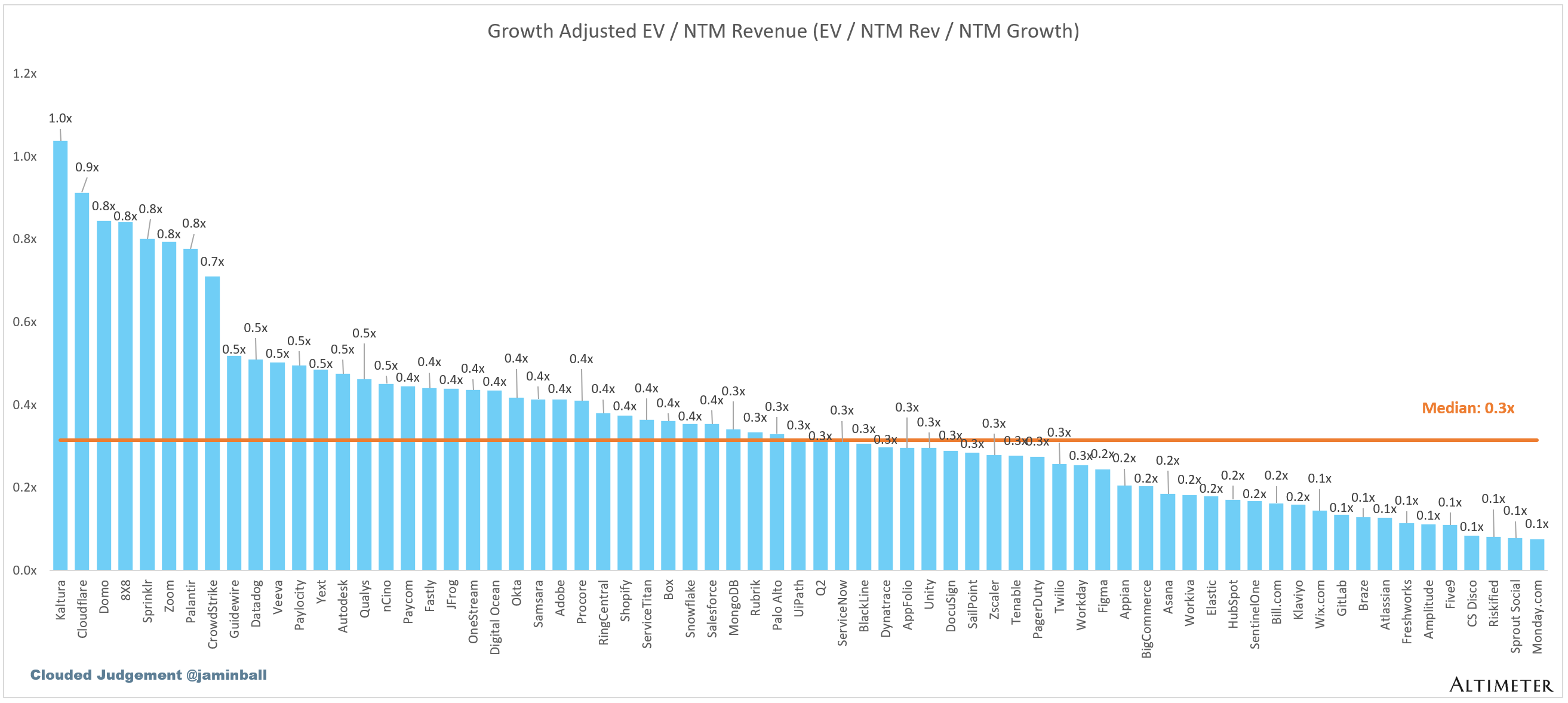
EV / NTM Rev / NTM Growth
The below chart shows the EV / NTM revenue multiple divided by NTM consensus growth expectations. So a company trading at 20x NTM revenue that is projected to grow 100% would be trading at 0.2x. The goal of this graph is to show how relatively cheap / expensive each stock is relative to its growth expectations.
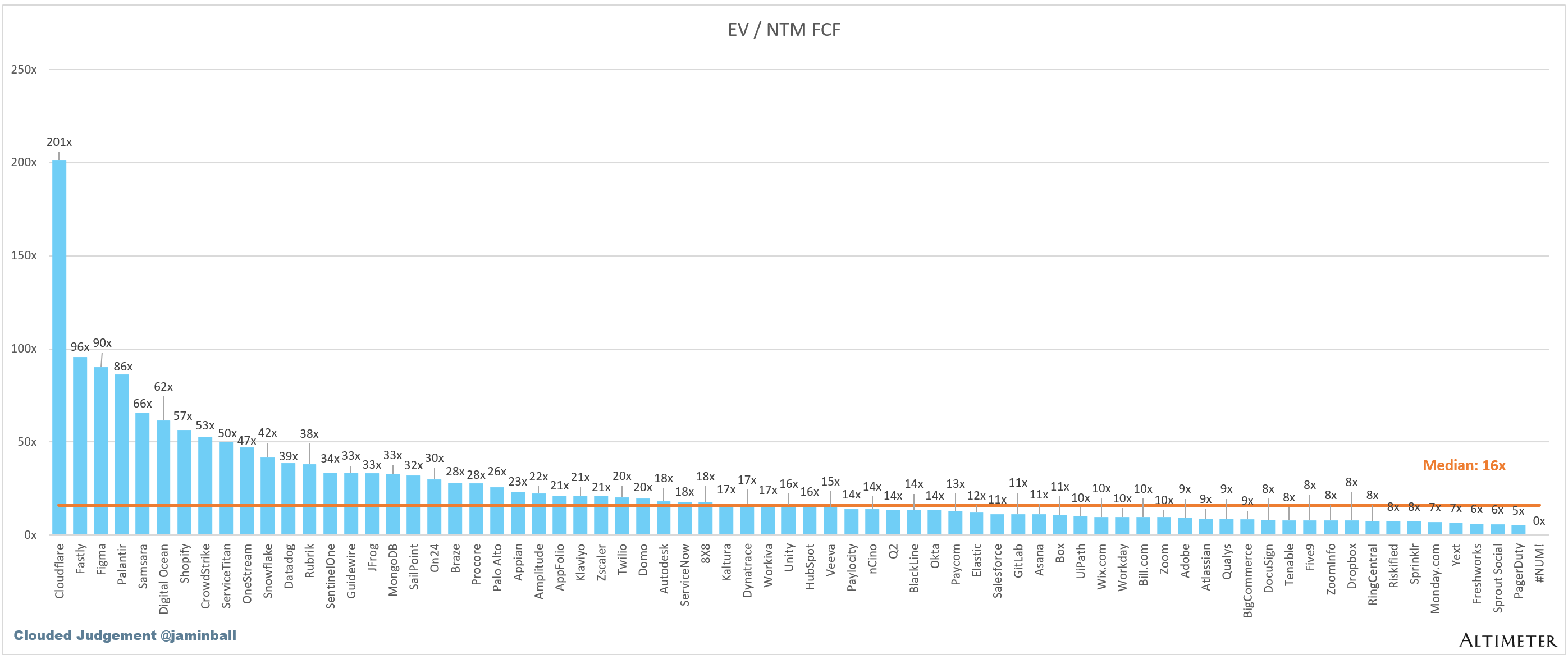
EV / NTM FCF
The line chart shows the median of all companies with a FCF multiple >0x and <100x. I created this subset to show companies where FCF is a relevant valuation metric.
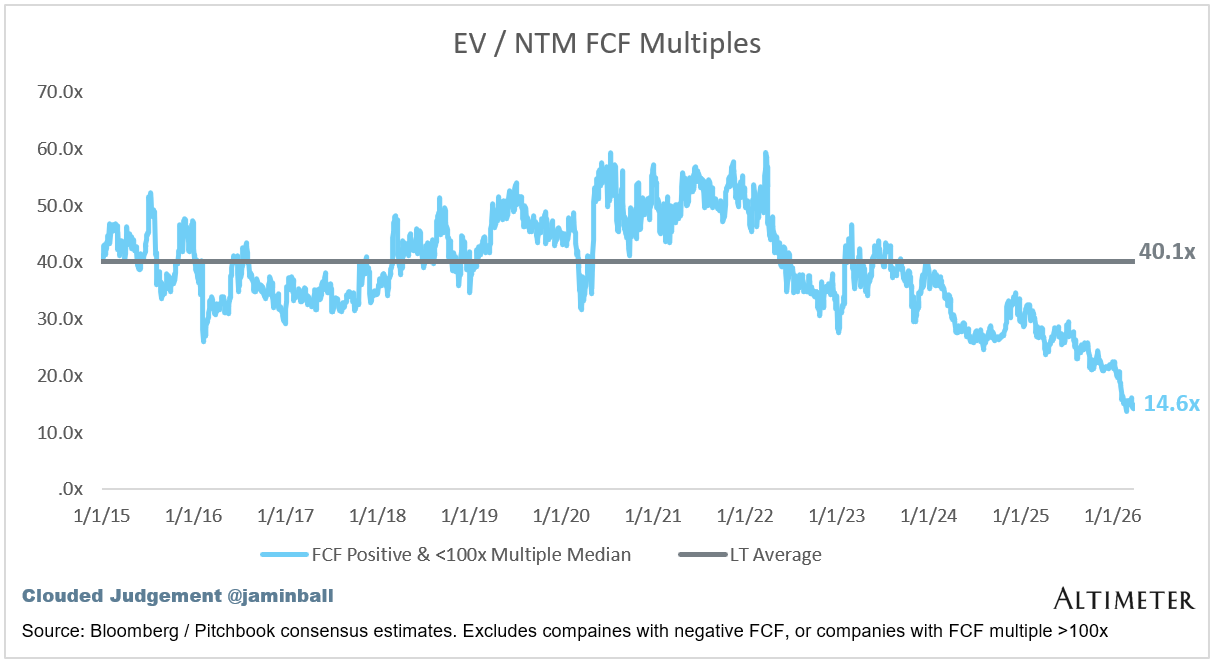
Companies with negative NTM FCF are not listed on the chart
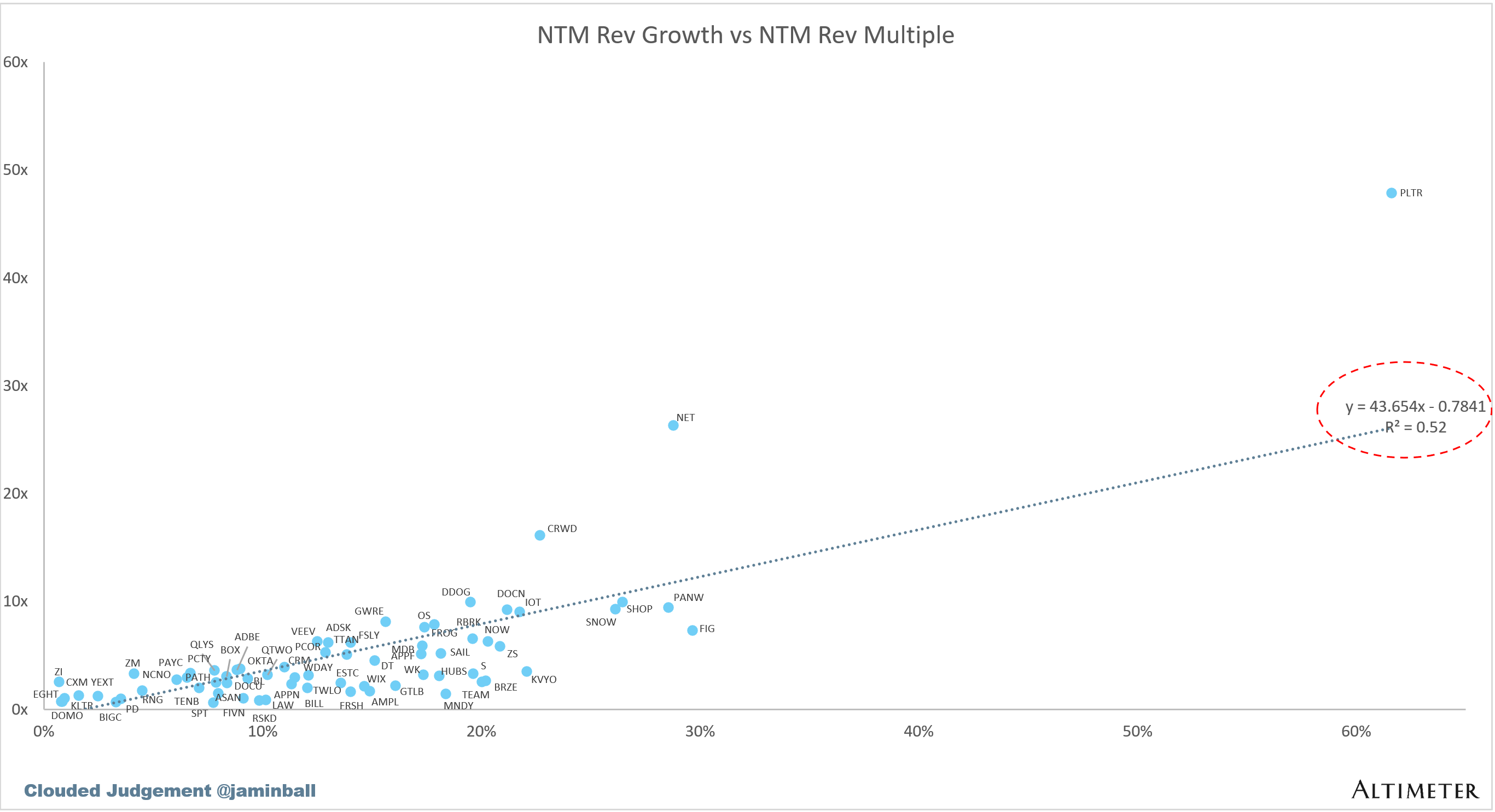
Scatter Plot of EV / NTM Rev Multiple vs NTM Rev Growth
How correlated is growth to valuation multiple?
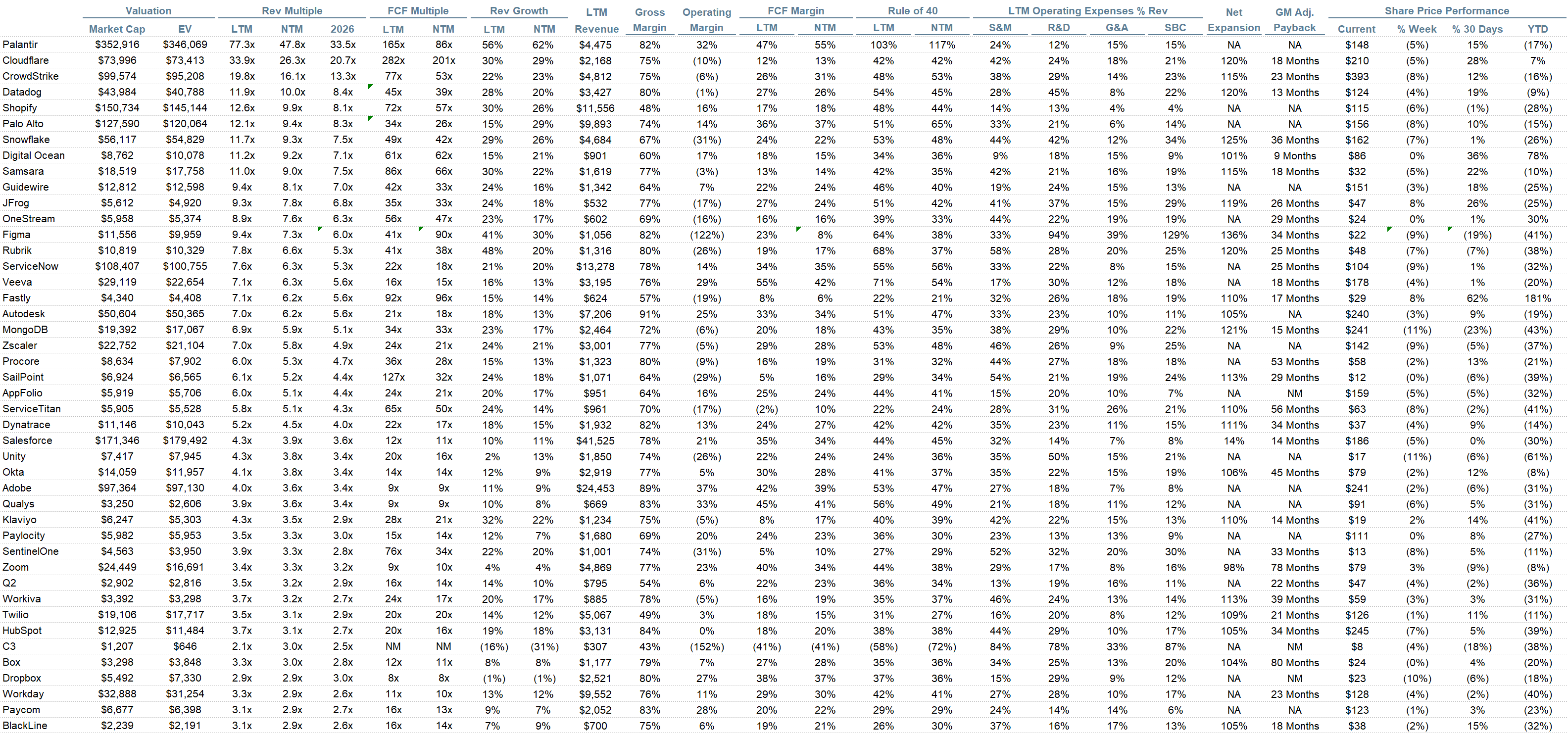
Operating Metrics
Median NTM growth rate: 13%
Median LTM growth rate: 15%
Median Gross Margin: 76%
Median Operating Margin (0%)
Median FCF Margin: 19%
Median Net Retention: 109%
Median CAC Payback: 33 months
Median S&M % Revenue: 35%
Median R&D % Revenue: 23%
Median G&A % Revenue: 15%
Comps Output
Rule of 40 shows rev growth + FCF margin (both LTM and NTM for growth + margins). FCF calculated as Cash Flow from Operations - Capital Expenditures
GM Adjusted Payback is calculated as: (Previous Q S&M) / (Net New ARR in Q x Gross Margin) x 12. It shows the number of months it takes for a SaaS business to pay back its fully burdened CAC on a gross profit basis. Most public companies don’t report net new ARR, so I’m taking an implied ARR metric (quarterly subscription revenue x 4). Net new ARR is simply the ARR of the current quarter, minus the ARR of the previous quarter. Companies that do not disclose subscription rev have been left out of the analysis and are listed as NA.
Sources used in this post include Bloomberg, Pitchbook and company filings
The information presented in this newsletter is the opinion of the author and does not necessarily reflect the view of any other person or entity, including Altimeter Capital Management, LP (”Altimeter”). The information provided is believed to be from reliable sources but no liability is accepted for any inaccuracies. This is for information purposes and should not be construed as an investment recommendation. Past performance is no guarantee of future performance. Altimeter is an investment adviser registered with the U.S. Securities and Exchange Commission. Registration does not imply a certain level of skill or training. Altimeter and its clients trade in public securities and have made and/or may make investments in or investment decisions relating to the companies referenced herein. The views expressed herein are those of the author and not of Altimeter or its clients, which reserve the right to make investment decisions or engage in trading activity that would be (or could be construed as) consistent and/or inconsistent with the views expressed herein.
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.
You mention "Under the token model, the equation flips. You’re now selling output vs raw compute time. A token that helps an agent close a sales deal is worth a lot more than a token that summarizes a Wikipedia page, even though they cost roughly the same to generate. That’s the whole point of Jensen’s tiered token pricing vision - different points on the Pareto curve command different price points." How do you differentiate between "Wikipedia summarization" and "Closing a Sales Deal"
Would love to attend a town hall on the topic. Elena Verna at Lovable led a similar discussion in December which was great.