
Clouded Judgement 4.18.25 - The Hidden Value in the AI Application Layer

Every week I’ll provide updates on the latest trends in cloud software companies. Follow along to stay up to date!
The Hidden Value in the AI Application Layer
The big headline in startup land this week: OpenAI is rumored to be acquiring Windsurf in a $3 billion deal. Windsurf (formerly known as Codeium) is a powerful coding assistant, similar to products from Cursor or GitHub copilot. In high level terms, these products use models (like a Sonnet 3.7 from Anthropic or GPT 4.1 from OpenAI) to power tools for developers (or non developers) to write code.
So why is this interesting? It shows (at some level, all depends on how real the rumors are) an interest from a “model company” to own more of the application layer. OpenAI has also talked about / previewed in recent interviews their own software engineering agent (SWE agent) that is on the horizon. Elsewhere, Anthropic recently launched Claude Code. It seems pretty clear we’ll see the AI labs move “up the stack” into more of the infra / application layers. One reason for this - if model API pricing gets commoditized you need other vectors to generate profits (not revenue, but profits). Applications powered by the models they create seem like a very natural extension. It does bring up an interesting channel conflict question - will OpenAI / Anthropic want to “enable” other coding assistants to compete with their own coding assistant application? Will they reserve the current state-of-the-art model for their own applications, while offering a slightly older version through the API, ensuring their apps always run on the best available model? Time will tell. I personally think (for the time being) they’ll solve for “max use of our models” and will always release current models in the API. But this could change if these model companies start to more and more become application companies. Regardless, I think one reason we’ll see more application acquisitions / application product announcements from the model companies is that there may be (for now) more profits to be farmed there (cue the pendulum swinging on the argument of GPT wrappers…).
But I think there’s another reason - maybe a bigger one. These applications generate a tremendous amount of DATA. One of the massive benefits to OpenAI of having ChatGPT is the treasure trove of multi-turn text data that users generate from their conversations with ChatGPT. If you’ve ever used ChatGPT and been asked to “select your preferred answer” between two options, that’s one part of their data feedback loop. All of the usage and text on ChatGPT helps make their models better. And text data is fairly basic - there’s tons of public text data on the interest. The same is true for code! However, a lot of code is not public (there is a ton in open source libraries, but a TON in non public repositories). One way to build a model like GPT 4.1 or Sonnet 3.7 is to start with a lot of code training data. And the more data you gather, the better you can make your models. Even more important, the more proprietary data you get, the better (and there’s lots of proprietary code data). Imagine the same workflow I mentioned above on ChatGPT but for code. A code editor suggests to autocompletes, and askes the user to select the one they prefer. This is very valuable data that will make their applications and models better.
The same will be true in other categories. Biology, life sciences, legal, healthcare, etc. And some of these categories’ data will skew even more private (ie won’t have a public set of data like open source repositories). So you need the application feedback loop (and thus the need to own the application layer). Without this, you’ll end up paying a fortune to the Scale AI / Surge / Mercor’s of the world. The bull case on any of these data labeling businesses is there will always be “the next” vertical to get labeled data from. You can get code data from your own application, or you can pay Scale to go out and find developers to write structured code for you.
Would OpenAI want to acquire Windsurf for the profits? The data? Something else? Fascinating times! Who else makes sense to get bought for the data?
Top 10 EV / NTM Revenue Multiples

Top 10 Weekly Share Price Movement

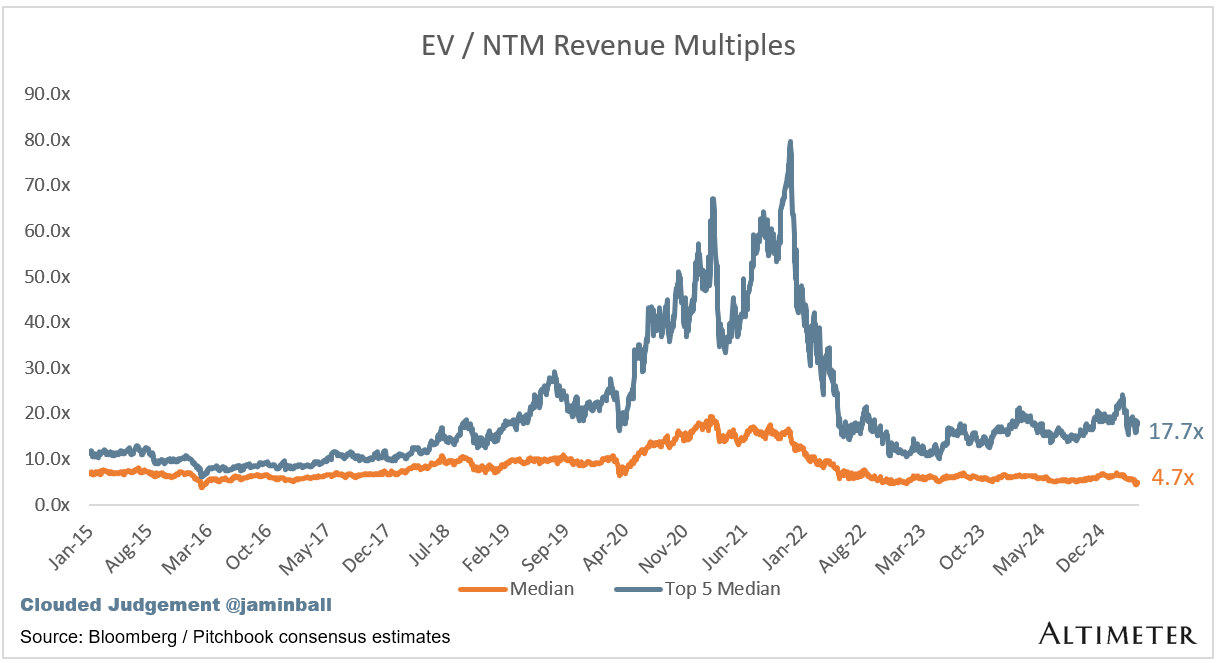
Update on Multiples
SaaS businesses are generally valued on a multiple of their revenue - in most cases the projected revenue for the next 12 months. Revenue multiples are a shorthand valuation framework. Given most software companies are not profitable, or not generating meaningful FCF, it’s the only metric to compare the entire industry against. Even a DCF is riddled with long term assumptions. The promise of SaaS is that growth in the early years leads to profits in the mature years. Multiples shown below are calculated by taking the Enterprise Value (market cap + debt - cash) / NTM revenue.
Overall Stats:
Overall Median: 4.7x
Top 5 Median: 17.7x
10Y: 4.3%

Bucketed by Growth. In the buckets below I consider high growth >27% projected NTM growth (I had to update this, as there’s only 1 company projected to grow >30% after this quarter’s earnings), mid growth 15%-27% and low growth <15%
High Growth Median: 13.7x
Mid Growth Median: 8.7x
Low Growth Median: 3.7x


EV / NTM Rev / NTM Growth
The below chart shows the EV / NTM revenue multiple divided by NTM consensus growth expectations. So a company trading at 20x NTM revenue that is projected to grow 100% would be trading at 0.2x. The goal of this graph is to show how relatively cheap / expensive each stock is relative to their growth expectations


EV / NTM FCF
The line chart shows the median of all companies with a FCF multiple >0x and <100x. I created this subset to show companies where FCF is a relevant valuation metric.

Companies with negative NTM FCF are not listed on the chart

Scatter Plot of EV / NTM Rev Multiple vs NTM Rev Growth
How correlated is growth to valuation multiple?

Operating Metrics
Median NTM growth rate: 11%
Median LTM growth rate: 15%
Median Gross Margin: 76%
Median Operating Margin (6%)
Median FCF Margin: 16%
Median Net Retention: 108%
Median CAC Payback: 43 months
Median S&M % Revenue: 39%
Median R&D % Revenue: 24%
Median G&A % Revenue: 16%
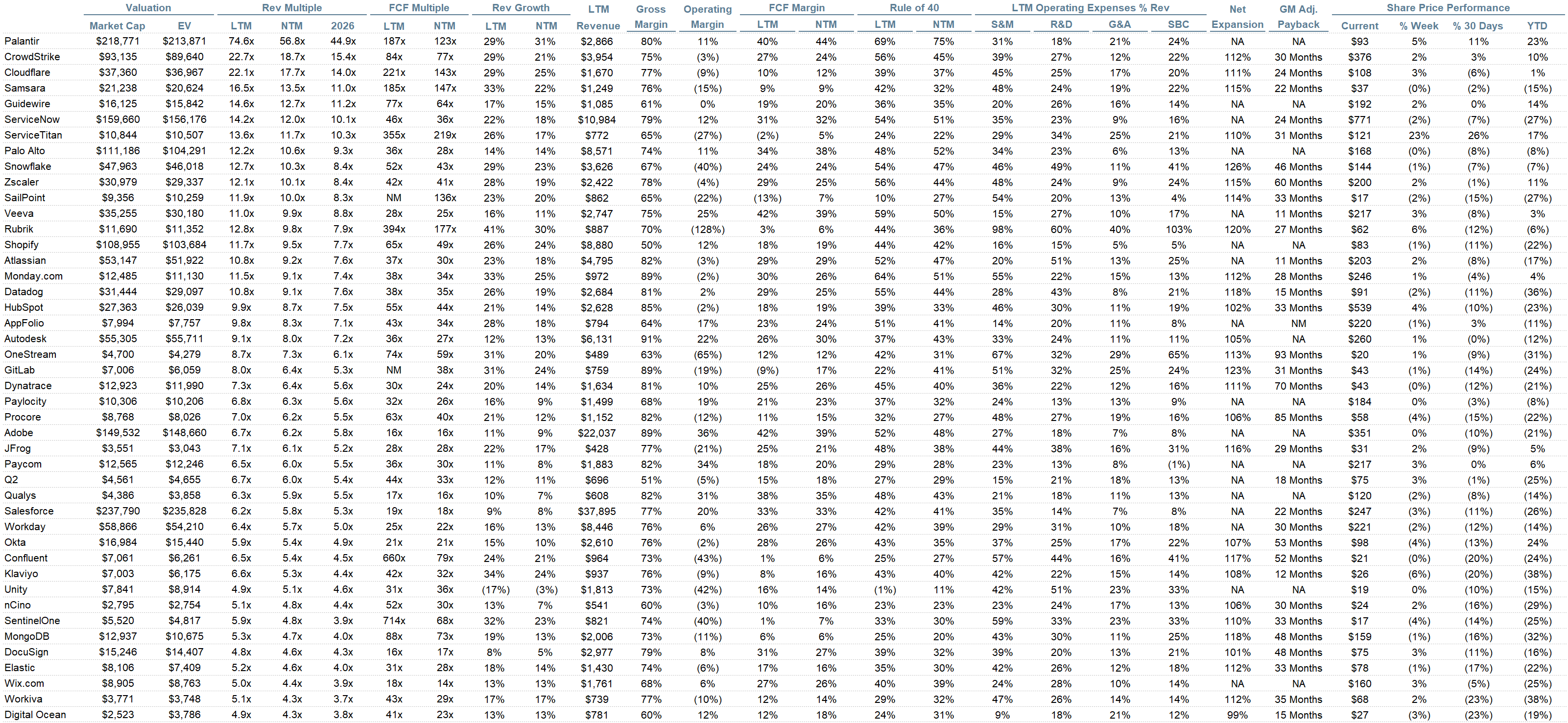
Comps Output
Rule of 40 shows rev growth + FCF margin (both LTM and NTM for growth + margins). FCF calculated as Cash Flow from Operations - Capital Expenditures
GM Adjusted Payback is calculated as: (Previous Q S&M) / (Net New ARR in Q x Gross Margin) x 12 . It shows the number of months it takes for a SaaS business to payback their fully burdened CAC on a gross profit basis. Most public companies don’t report net new ARR, so I’m taking an implied ARR metric (quarterly subscription revenue x 4). Net new ARR is simply the ARR of the current quarter, minus the ARR of the previous quarter. Companies that do not disclose subscription rev have been left out of the analysis and are listed as NA.

Sources used in this post include Bloomberg, Pitchbook and company filings
The information presented in this newsletter is the opinion of the author and does not necessarily reflect the view of any other person or entity, including Altimeter Capital Management, LP ("Altimeter"). The information provided is believed to be from reliable sources but no liability is accepted for any inaccuracies. This is for information purposes and should not be construed as an investment recommendation. Past performance is no guarantee of future performance. Altimeter is an investment adviser registered with the U.S. Securities and Exchange Commission. Registration does not imply a certain level of skill or training.
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.
Is there a reason why SoundHound is not included in the table?