
Clouded Judgement 6.30.23 - Data + Compute = AI

Every week I’ll provide updates on the latest trends in cloud software companies. Follow along to stay up to date!
Data + Compute = AI
Two of the largest data companies in the world, Snowflake and Databricks, held their annual conferences this week. Tons of takeaways and exciting product announcements from each, but the one quote that I believe summarizes both conferences perfectly was something Frank Slootman said in his opening keynote:
“In order to have an AI strategy, you need a data strategy”
I couldn’t agree more with this. Foundation models and their outputs are only as good as the data that feeds / trains them. And as we move from general purpose LLM engines (think ChatGPT) to enterprise specific engines (models trained on enterprise specific data), companies need to get their data in order. The idea that LLMs will be able to scour every system within an enterprise and grab data where it lies (both unstructured and structured) is not something I believe will happen. It ignores things like cost and performance. To truly take advantage of AI, enterprises need organized data in the cloud.
Most of the work / output from foundation models today are probabilistic. Said another way, the outputs are “best guesses” at an answer based on it’s training data. I could ask ChatGPT “Why is the Super Bowl a popular television event?” and I’ll get a different answer every time. And it doesn’t really matter that the answer is different every time. The challenge is probabilistic answers don’t work for true enterprise specific AI. We need to move to a world of deterministic output / answers. We need to know the output is accurate. If I’m a consumer subscription company and I ask an AI “What is my 30 day customer retention, how has it trended over the last 6 months, and if it’s changing what’s causing the change?” I need to know that the answer I get back is accurate. Based on the answer, I may make different business decisions. Generative AI is great because it will democratize knowledge extraction data, but we need to augment foundation models with enterprise specific data through the power of retrieval and search (one such method is called Retrieval Augmented Generation, or RAG). RAG helps solve a key problem - LLMs only know about data they were trained on. We need to train or fine tune models on specific enterprise data OR augment them through search and retrieval of enterprise data. And the key variable is organized data in the cloud. In order to train, fine tune, or retrieve data to super-charge enterprise foundation models, companies need organized data. ie they need a data strategy. And we’re starting to see this play out. Every company knows they need to have an AI strategy. But exactly what that will be isn’t quite clear. What is clear is step 1 is getting your data in order.
Why is this important? Extracting knowledge from data is only act 1 of the current wave of AI. The outputs of AI today are largely for human consumption. Humans take that output, and then make business decisions. The (way more) interesting wave of AI, in my opinion, is when the output of AI is consumed by machines. A machine takes the output of an AI and takes an action. We’re starting to see this a bit with the emergence of AI agents. Let’s go back to the above question: “What is my 30 day customer retention, how has it trended over the last 6 months, and if it’s changing what’s causing the change?” Let’s say the answer from the foundation model is “your customer retention has degraded because the 5% off promotion you ran expired.” A human will have to drill in, debug, and verify the answer. But what if we didn’t need the human in the loop? What if a machine could take that output, and turn the promotion back on? THAT will be truly game changing. BUT - the key variable is moving to deterministic AI systems. And to do that, we need organized data in the cloud.
Wrapping this up with a final thought from Jensen (Nvidia CEO) at the Snowflake Summit. I’m paraphrasing, but he said something along the lines of “we used to bring data to the compute…but now the data is massive, needs to be secured, etc. It’s hard to move data around. It’s easier to bring the Nvidia compute engine to the data.” I loved this quote. While data is the first ingredient of AI, the other just as important ingredient is compute. Adding them together, we get AI!
Data + Compute = AI
Snowflake Investor Day
During the investor portion of Snowflake Summit, their CFO mentioned that daily consumption patterns were normalizing in June back above the April / May lows where they say flat week over week growth. This was a positive sign for the rest of the consumption software universe
Top 10 EV / NTM Revenue Multiples
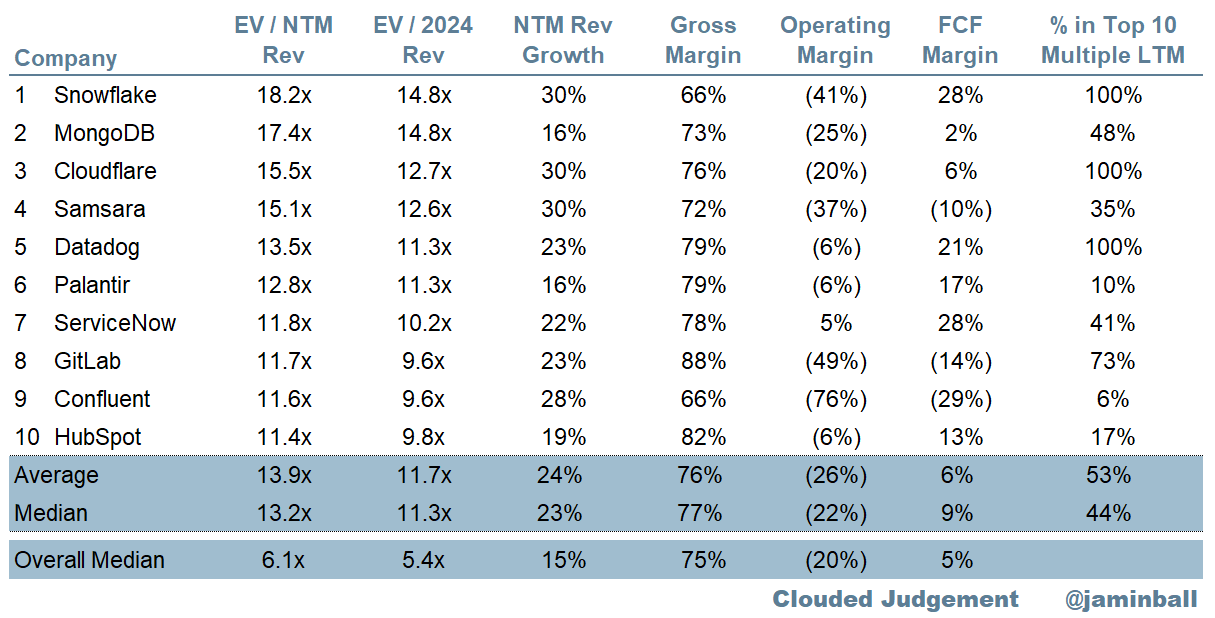
Top 10 Weekly Share Price Movement

Update on Multiples
SaaS businesses are generally valued on a multiple of their revenue - in most cases the projected revenue for the next 12 months. Revenue multiples are a shorthand valuation framework. Given most software companies are not profitable, or not generating meaningful FCF, it’s the only metric to compare the entire industry against. Even a DCF is riddled with long term assumptions. The promise of SaaS is that growth in the early years leads to profits in the mature years. Multiples shown below are calculated by taking the Enterprise Value (market cap + debt - cash) / NTM revenue.
Overall Stats:
Overall Median: 6.1x
Top 5 Median: 15.5x
10Y: 3.9%


Bucketed by Growth. In the buckets below I consider high growth >30% projected NTM growth, mid growth 15%-30% and low growth <15%
High Growth Median: 9.6x
Mid Growth Median: 8.7x
Low Growth Median: 3.6x

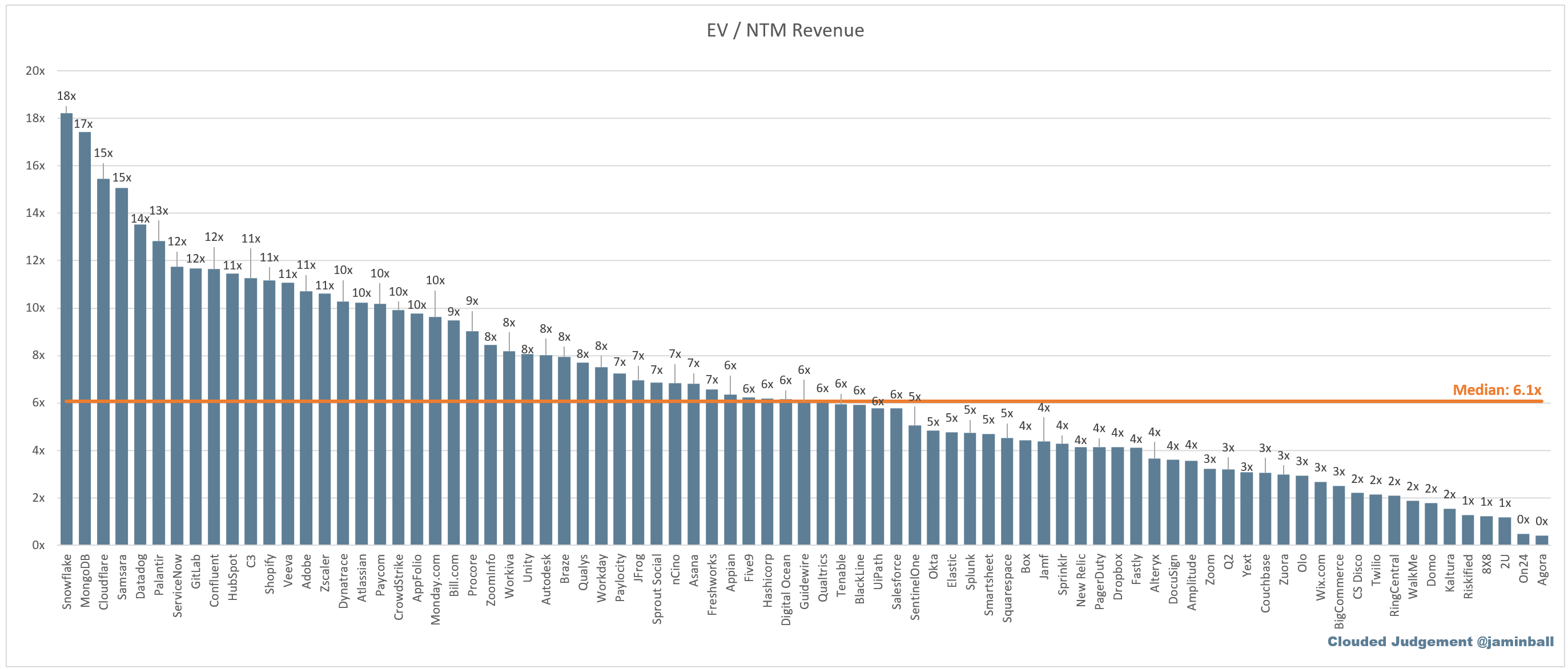
EV / NTM Rev / NTM Growth
The below chart shows the EV / NTM revenue multiple divided by NTM consensus growth expectations. The goal of this graph is to show how relatively cheap / expensive each stock is relative to their growth expectations

EV / NTM FCF
Companies with negative NTM FCF are not listed on the chart
Scatter Plot of EV / NTM Rev Multiple vs NTM Rev Growth
How correlated is growth to valuation multiple?

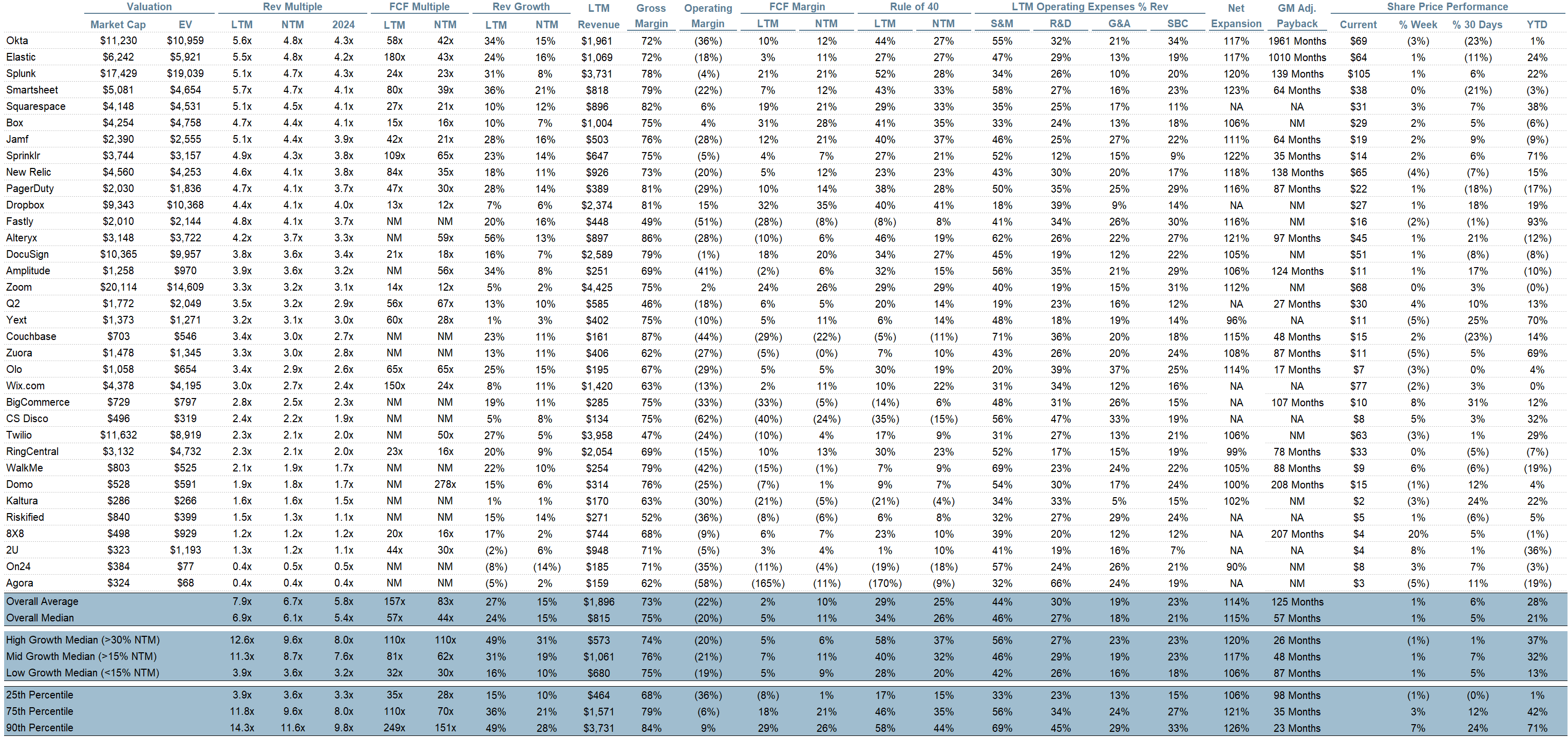
Operating Metrics
Median NTM growth rate: 15%
Median LTM growth rate: 24%
Median Gross Margin: 75%
Median Operating Margin (20%)
Median FCF Margin: 5%
Median Net Retention: 115%
Median CAC Payback: 57 months
Median S&M % Revenue: 46%
Median R&D % Revenue: 27%
Median G&A % Revenue: 18%
Comps Output
Rule of 40 shows rev growth + FCF margin (both LTM and NTM for growth + margins). FCF calculated as Cash Flow from Operations - Capital Expenditures
GM Adjusted Payback is calculated as: (Previous Q S&M) / (Net New ARR in Q x Gross Margin) x 12 . It shows the number of months it takes for a SaaS business to payback their fully burdened CAC on a gross profit basis. Most public companies don’t report net new ARR, so I’m taking an implied ARR metric (quarterly subscription revenue x 4). Net new ARR is simply the ARR of the current quarter, minus the ARR of the previous quarter. Companies that do not disclose subscription rev have been left out of the analysis and are listed as NA.

This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.
Awesome piece and one of your very best I must say
Shouldn`t the CAC Payback be: (Previous Q S&M) / (Net New ARR in Q x Gross Margin) = Number of Quarters which then times 4 should get you the number of months?