
Clouded Judgement 6.5.26 - Where Are the American Open Source Models?

Every week I’ll provide updates on the latest trends in cloud software companies. Follow along to stay up to date!
Where Are the American Open Source Models?
I’ve been investing in open source companies for nearly my entire venture career. I love open source businesses, think they’re generally great for the ecosystem, and can also create a lot of commercial value (but this can be tricky!). We’ve seen all kinds of open source businesses become successful. Databases (Mongo, Clickhouse, etc), Data Infrastructure (Databricks, Confluent, etc) Developer Tools (Hashicorp, GitLab, etc). And many other categories.
The nuance lies in how you define “open source.” A lot of this comes down to what open source license the open source project uses. At a high level there are three main buckets. First is fully open and permissive (MIT, Apache 2.0, etc) - anyone can use, modify, and distribute the code however they want, including building commercial products on top of it. Second is copyleft (GPL, AGPL, etc) - the code is open, but if you distribute or build on it you have to open source your own code too. Third is source available - the code is publicly readable but the license restricts commercial use in specific ways. This is where you see licenses like BSL (Business Source License) and SSPL, which HashiCorp and MongoDB have both moved to at various points. The main point with source available licenses is that you can basically do everything you can in the permissive license, EXCEPT monetize the project (ie you can’t take the project, create a hosted version, and charge for it). The most “pure” opensource proponents would say only the fully open and permissive licenses are truly open source. Everything else isn’t.
The playbook for many of these open source companies was / is to first become the default in their field. This is the most important part. Spark became the default in large scale data processing, Kafka became the default for real time data streaming and event ingestion. Mongo for NoSQL databases. Etc. Each project became widespread and ubiquitous in their respective fields - they were / are the dominant platform for their use case. Then the commercial companies behind each project figured out a way to monetize. Sometimes this was through hosted offerings - where the company runs and manages the infrastructure for you, so you don't have to worry about deploying, scaling, or maintaining the project yourself. In other instances, proprietary features were gated behind a commercial offering (this could be better performance, enterprise features, etc). Regardless - there were playbooks to monetize, and successful examples of large commercial businesses being built on top of successful open source projects.
But this wasn’t always the case. For a long time, the conventional wisdom was that open source couldn't be a real business. If the code is free, who pays? And the skepticism was genuine - why would a company pay for something their engineers could just download and run themselves? Early open source companies had to fight hard to prove out the commercial model, and a lot of investors passed on these deals early on because the business logic wasn't obvious. "You're just going to give it away?" was a common reaction. And honestly, it wasn't an unreasonable question. The answer turned out to be: yes, you give the software away, but you charge for everything around it - the hosted version, the enterprise features, the support, the integrations, the proprietary engines, etc. The open source project served as distribution, and the commercial product was something different. And after a wave of successful open source commercial companies emerged, it became more obvious what was possible (commercially). And this was very important - investors (like myself) deeply believed successful open source projects could translate into successful commercial companies. This created an important incentive set - an incentive to fund open source companies (by investors) and an incentive to start commercial open source companies (by founders)
Let me tie this back to what’s happening in open source AI. Today, one of the biggest disappointments is a lack of a strong open source model ecosystem in the US. All of the frontier models are closed source from OpenAI / Anthropic. The leading opensource models are largely all from Chinese labs. DeepSeek being the most prominent example, but also Qwen from Alibaba, Kimi from Moonshot AI, and others. Jensen Huang has talked about the importance of having American leaders at every layer of the AI stack - chips, models, infrastructure, applications. The US is clearly winning at chips (Nvidia) and has strong incumbents at the application layer, but the open source model layer is a real gap. And that gap matters more than people realize. Open source models are how developers learn, experiment, and build. They're the distribution layer for the next generation of AI applications. If the dominant open source models all come from Chinese labs, that has long term implications for where developer communities form, where tooling gets built around, and ultimately where commercial ecosystems emerge.
So why hasn’t there been more of a blossoming US open source model ecosystem? I think it all comes down to incentives. In the same way investors had questions about the business model of open source companies many years ago, they have similar questions about open source labs today. How do you monetize an open source model? You could “host” it - which in the case of models probably means just means hosting an API endpoint people can hit for inference. BUT if you’re doing this you’re also going to directly compete with anyone else who can pick up your model and host an inference API endpoint. Baseten, Fireworks, all the hyperscalers, etc. And the question then becomes do you as the model provider have an advantage that lets you serve the model either more performantly or more cost efficiently (or both). The answer to this question is probably “maybe” but not by enough to win with high margins over the long term.
The next natural place is to move into fine tuning / eval feedback loops. Most folks want to take an open source model, fine tune it for their use case / data, observe / monitor / improve that fine tuned model (and rinse repeat). So the open source labs could move into this line of business and charge for it. But then you’re still going to compete with the Fireworks / Baseten / Hyperscalers who will also offer this.
And then there’s the question of what does it mean to be an open source model? There's actually a spectrum here too - and it maps pretty cleanly to the licensing buckets we talked about earlier. The MIT / Apache equivalent in the model world would be truly open weights with no commercial restrictions - download it, fine tune it, host it, build a business on top of it, do whatever you want. The source available equivalent would be something like Llama - the weights are publicly available, you can experiment and build, but there are commercial restrictions that kick in at scale. And then true open source, the equivalent of releasing the full source code, would mean releasing not just the weights but the training data, the training pipeline, the evals, everything needed to fully replicate the model from scratch. Almost nobody does this. So when we talk about the "open source model ecosystem," we're really mostly talking about open weights models with varying degrees of commercial restrictions. Which matters, because just like source available licenses changed the commercial dynamics for traditional open source companies, the restrictions baked into open weights models will shape where developer communities form, what gets built on top, and ultimately who captures the commercial value.
I think the main issue facing the open source model ecosystem is incentives. People (ie investors) just question the business feasibility of open source models. Today, most of the world is using the frontier models for everything. However, what’s really come into focus very recently is costs. It just doesn’t make sense to drive the Ferrari down the street to the grocery store…The Honda will do just fine. You don’t need the “expensive frontier” tokens for everything. I don’t know where the line is, but let’s just use the 80/20 rule. Maybe 80% of the use cases are generic enough where a smaller, less powerful, but cost efficient model will do fine. And for the 20% of use cases you’ll really need the frontier expensive tokens (i’m completely making up that ratio, just using an illustrative example).
So then - why shouldn’t open source dominate in this next part of the cycle?? When people shift usage from most expensive tokens to cheaper tokens, wouldn’t open source be the natural alternative? Yes - but where are the models?? The other baked in assumption is that the open source models are “good enough.” Said another way, the gap between the frontier closed source models and open source isn’t “that wide” (and more importantly is the trajectory widening or closing).
Right now all the best open source models Chinese models… And these models have largely gotten to where they are by distilling frontier models. But I think that was much easier when the models were more “basic” language models. Question / answer type models where you could create a data set by asking millions of questions to the frontier model. I think distillation is getting harder. The most frontier models are now being released with increasingly complex harnesses. Or the frontier models aren’t released via an API but are wrapped into a product themselves. Or look at Claude - playing around with Claude Code, I have workstreams that kick off 50+ agents in parallel. How do you distill a model with 50+ agents running in parallel?? It’s much harder than just getting millions of question / answer pairs… All of this makes it much harder to “distill.” And the cost to pre-train (without the head start of distilling) is massive. All of this to say - I find myself today probably on the side of the gap widening (not shrinking) between the frontier and open source.
So who will be able to raise massive amounts of money, to pre-train a model, that will maybe work, but might end up being too far behind the frontier to capture real market share, and even if you get all of the previous points right there are still questions about how you monetize over the long haul (the first half of this post). Everyone WANTS this to happen. But who’s going to fund it?
I go back to the early days of Neoclouds where Nvidia really propped up the ecosystem. They funded (massively) a class of companies who might not have gotten the funding elsewhere. Do we need King Jensen again?? Or do we need governments to fund it out of a sovereign interest?? I’m not sure. But I really hope the US open source ecosystem finds a way to thrive.
What I think it will take - some sort of research breakthrough that open source gets first. Let’s hope that happens! I also think (no inside info) at some point the closed source frontier labs will get back into open sourcing models. Maybe not the frontier. Maybe a slimmed down version of the frontier, or maybe open sourcing one model release prior to the frontier. This is the most hopeful scenario!
Quarterly Reports Summary
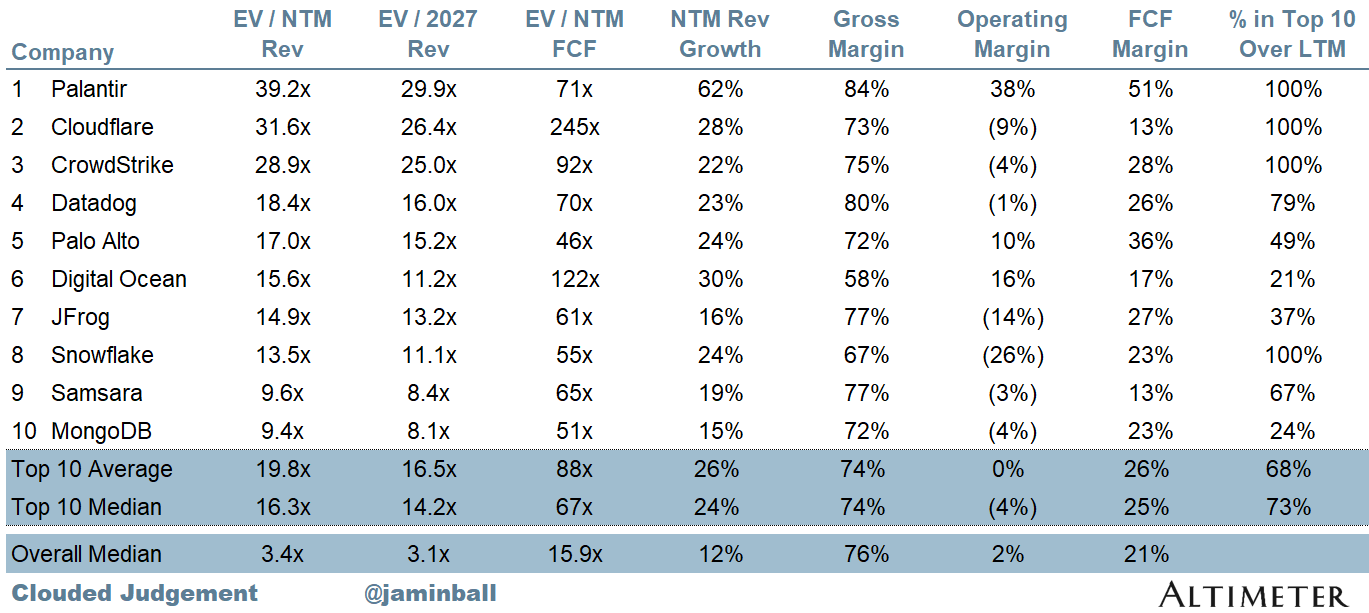
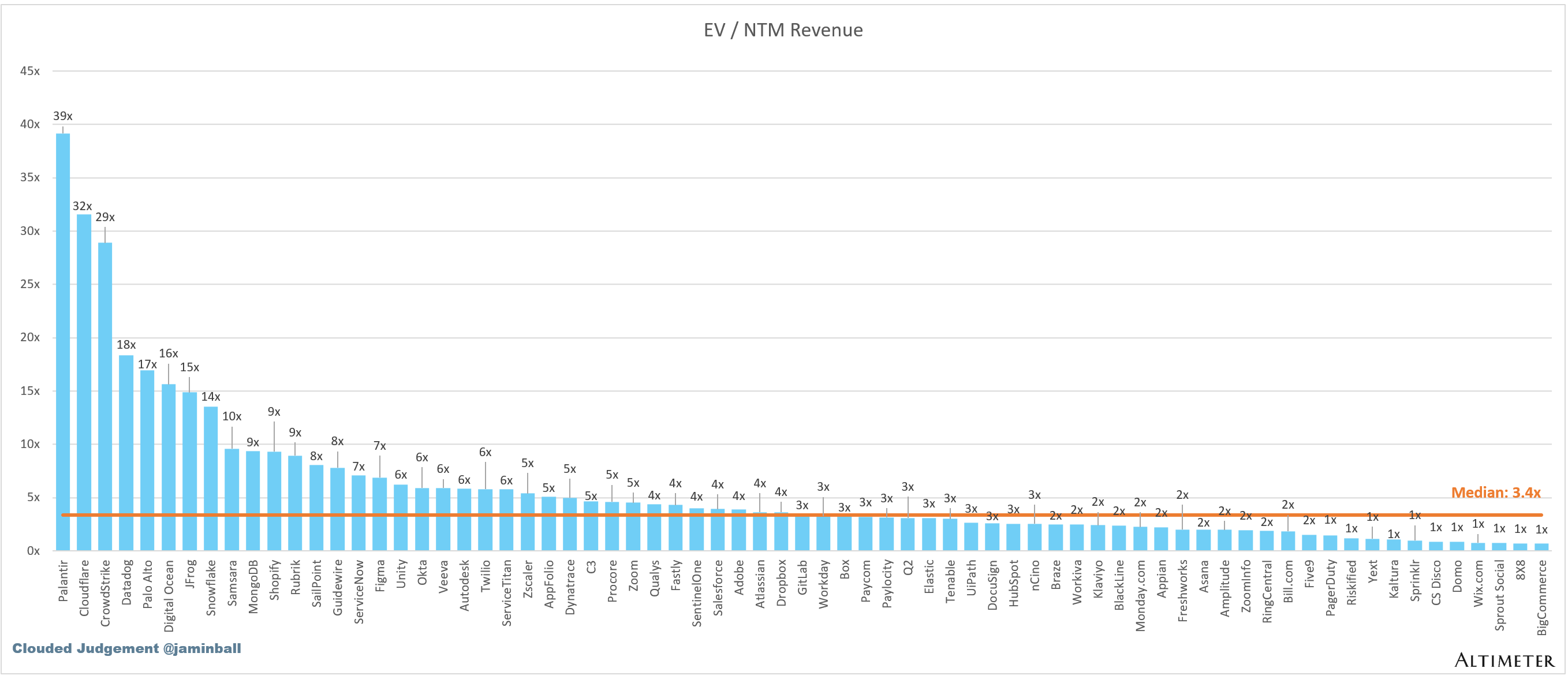
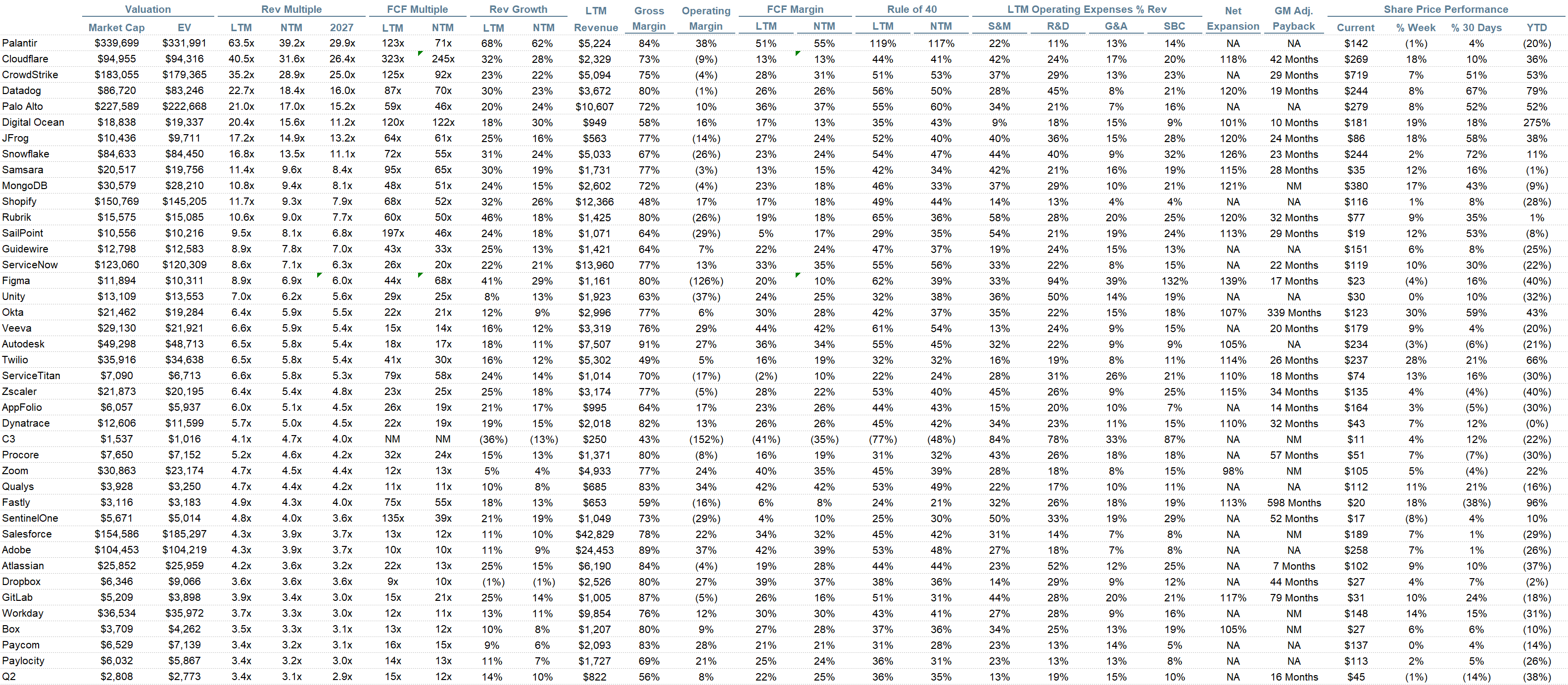
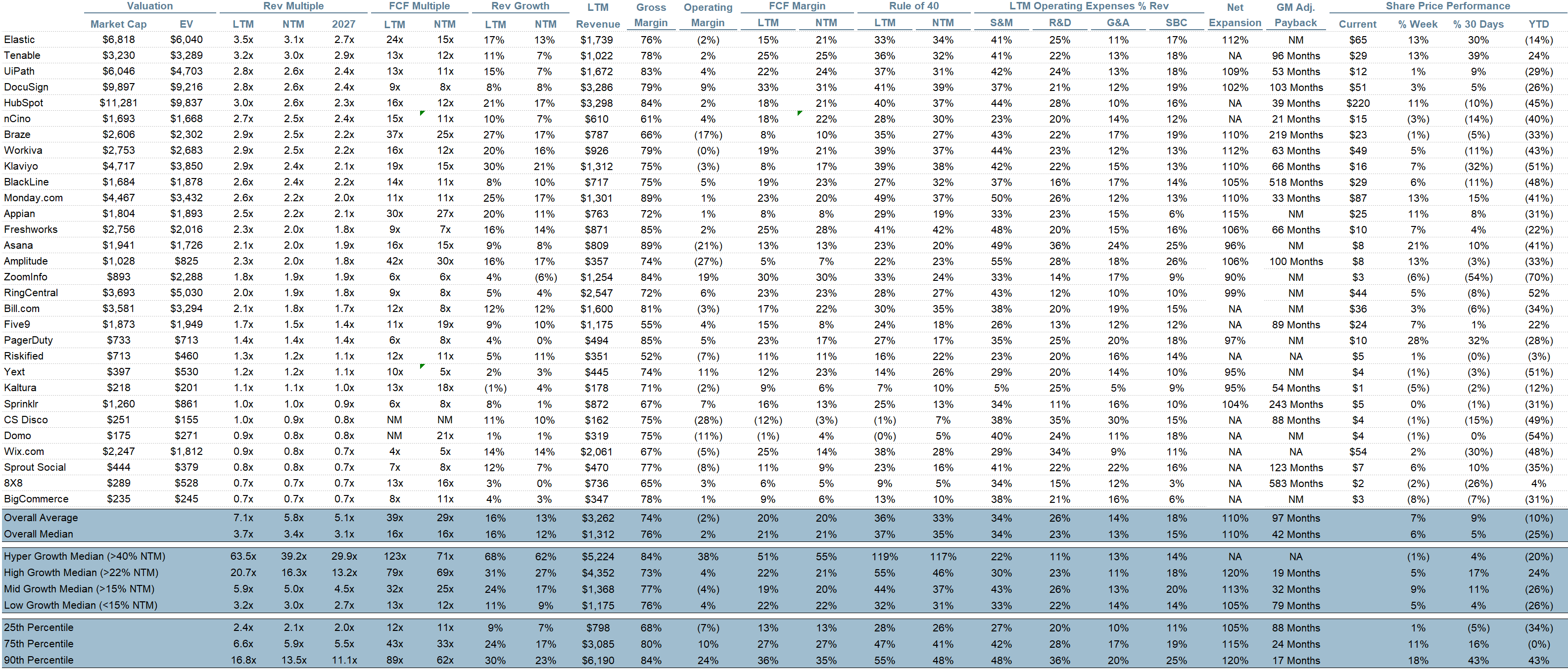
Top 10 EV / NTM Revenue Multiples
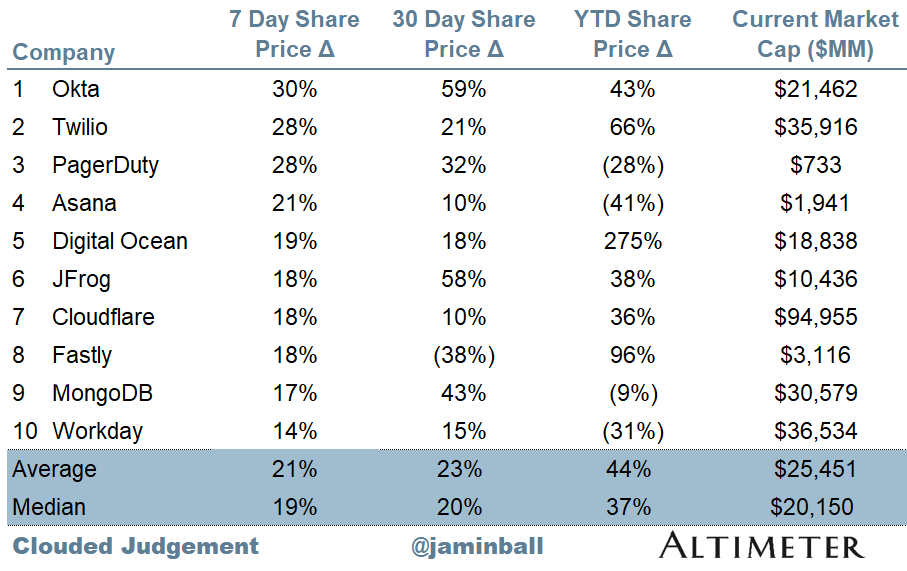
Top 10 Weekly Share Price Movement
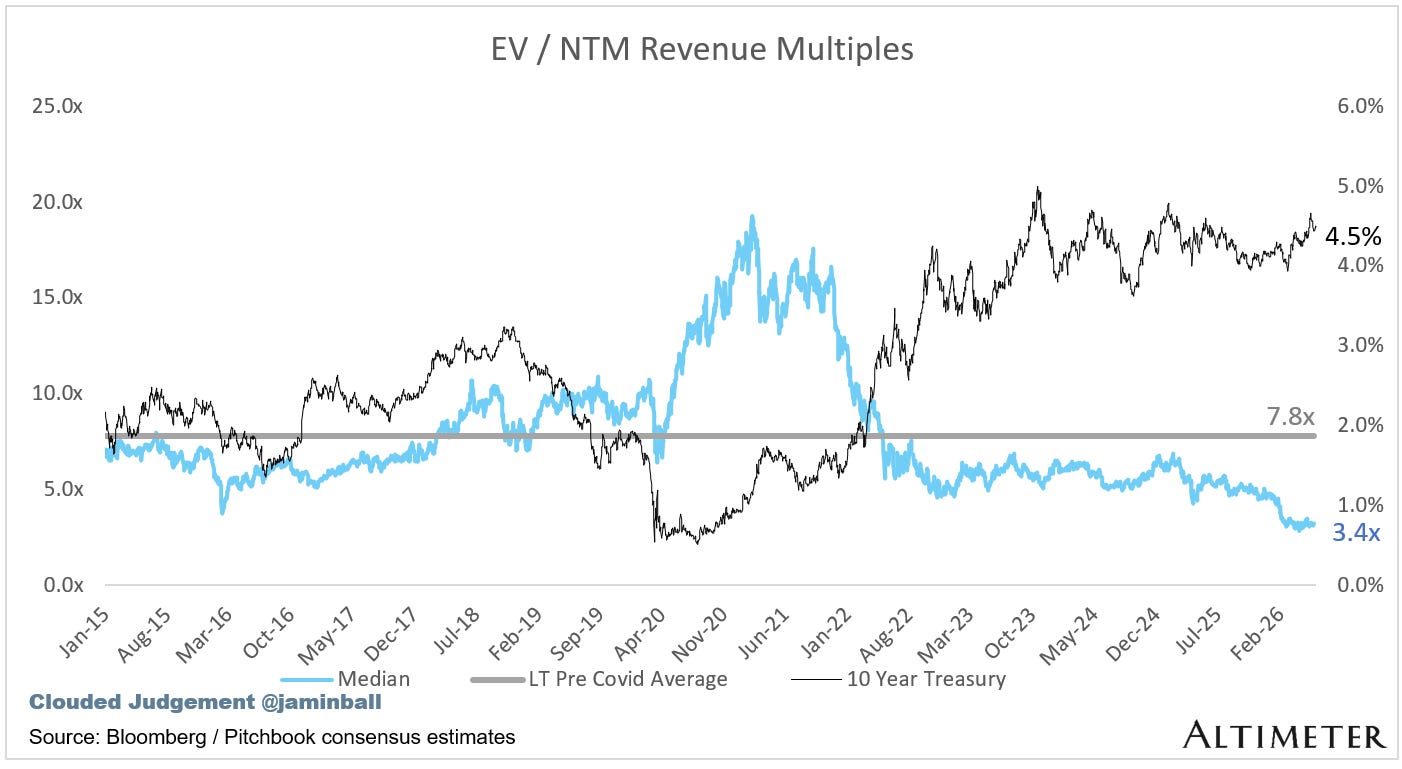
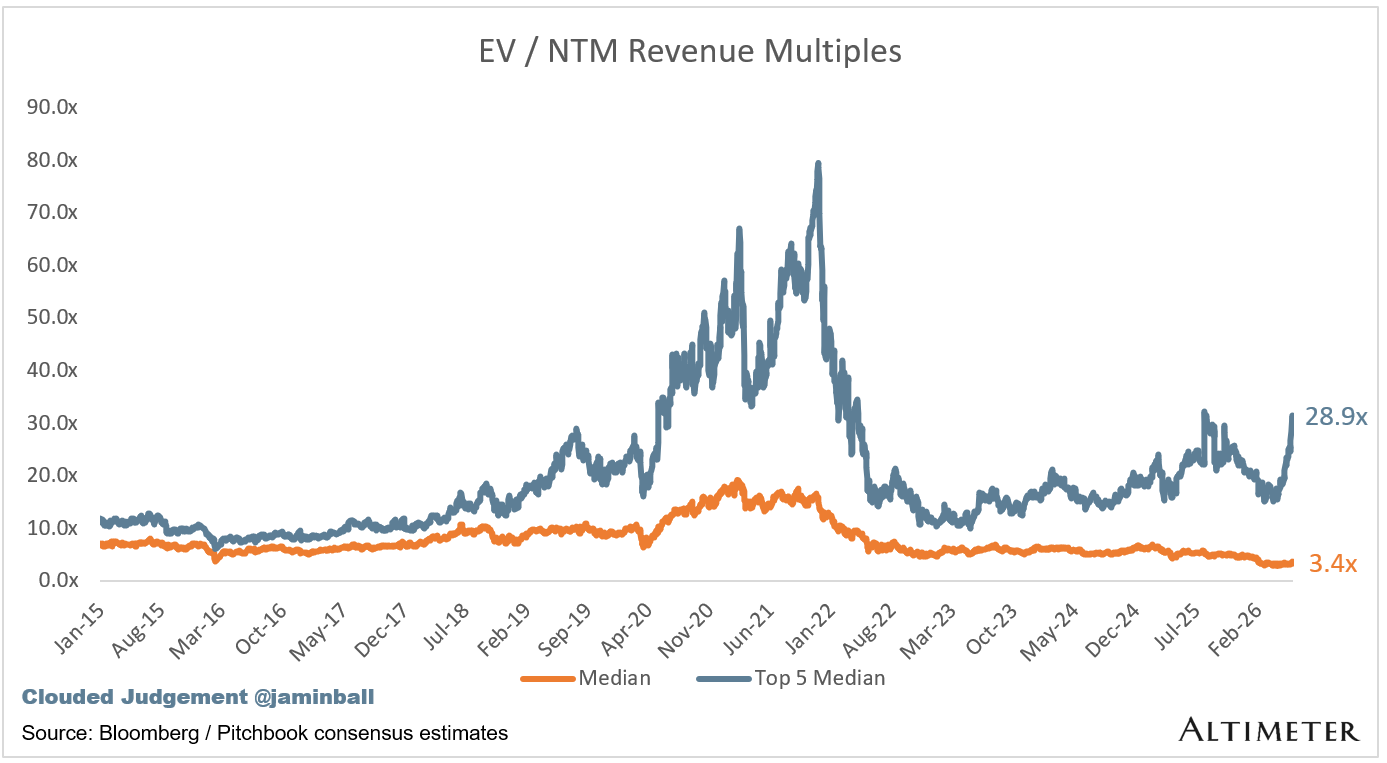
Update on Multiples
SaaS businesses are generally valued on a multiple of their revenue - in most cases the projected revenue for the next 12 months. Revenue multiples are a shorthand valuation framework. Given most software companies are not profitable, or not generating meaningful FCF, it’s the only metric to compare the entire industry against. Even a DCF is riddled with long term assumptions. The promise of SaaS is that growth in the early years leads to profits in the mature years. Multiples shown below are calculated by taking the Enterprise Value (market cap + debt - cash) / NTM revenue.
Overall Stats:
Overall Median: 3.4x
Top 5 Median: 28.9x
10Y: 4.5%
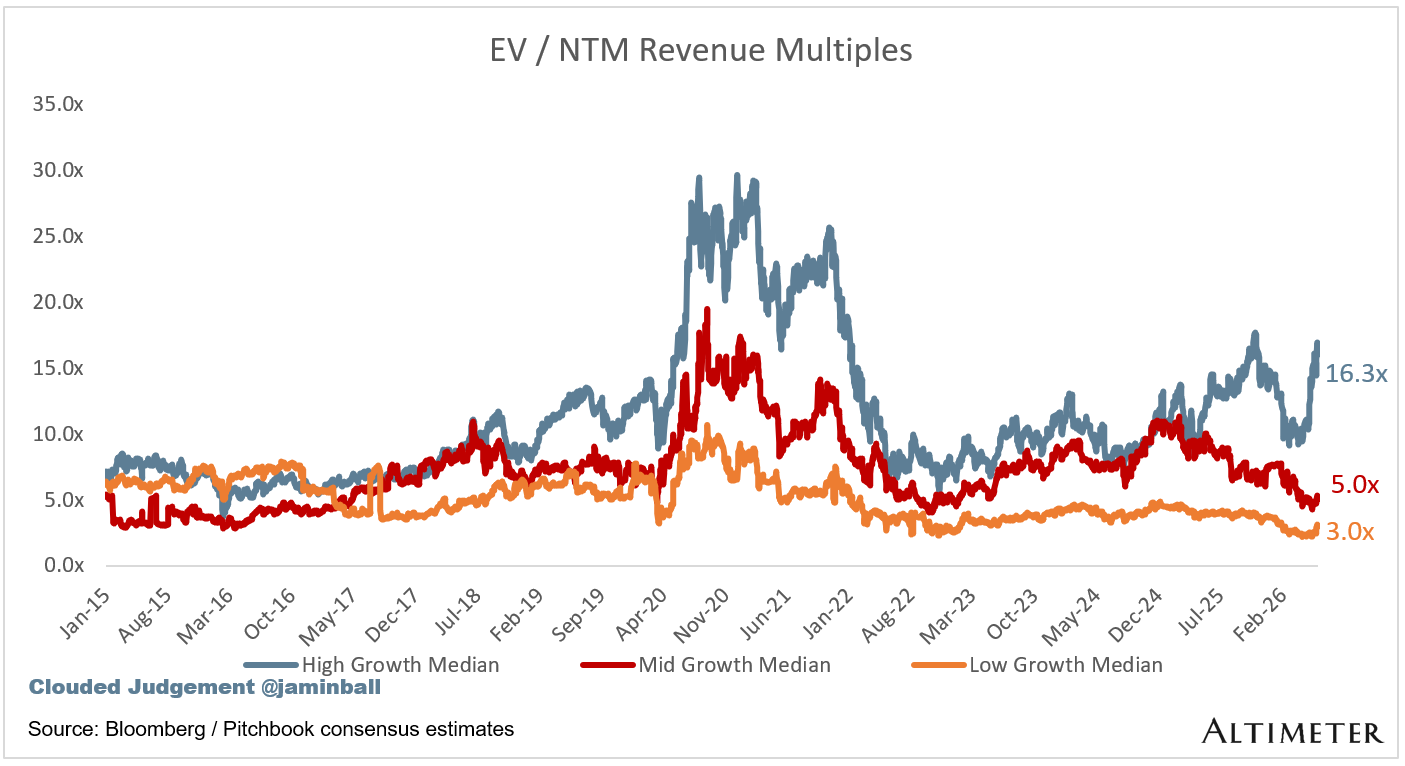
Bucketed by Growth. In the buckets below I consider high growth >22% projected NTM growth, mid growth 15%-22% and low growth <15%. I had to adjusted the cut off for “high growth.” If 22% feels a bit arbitrary, it’s because it is…I just picked a cutoff where there were ~10 companies that fit into the high growth bucket so the sample size was more statistically significant
High Growth Median: 16.3x
Mid Growth Median: 5.0x
Low Growth Median: 3.0x
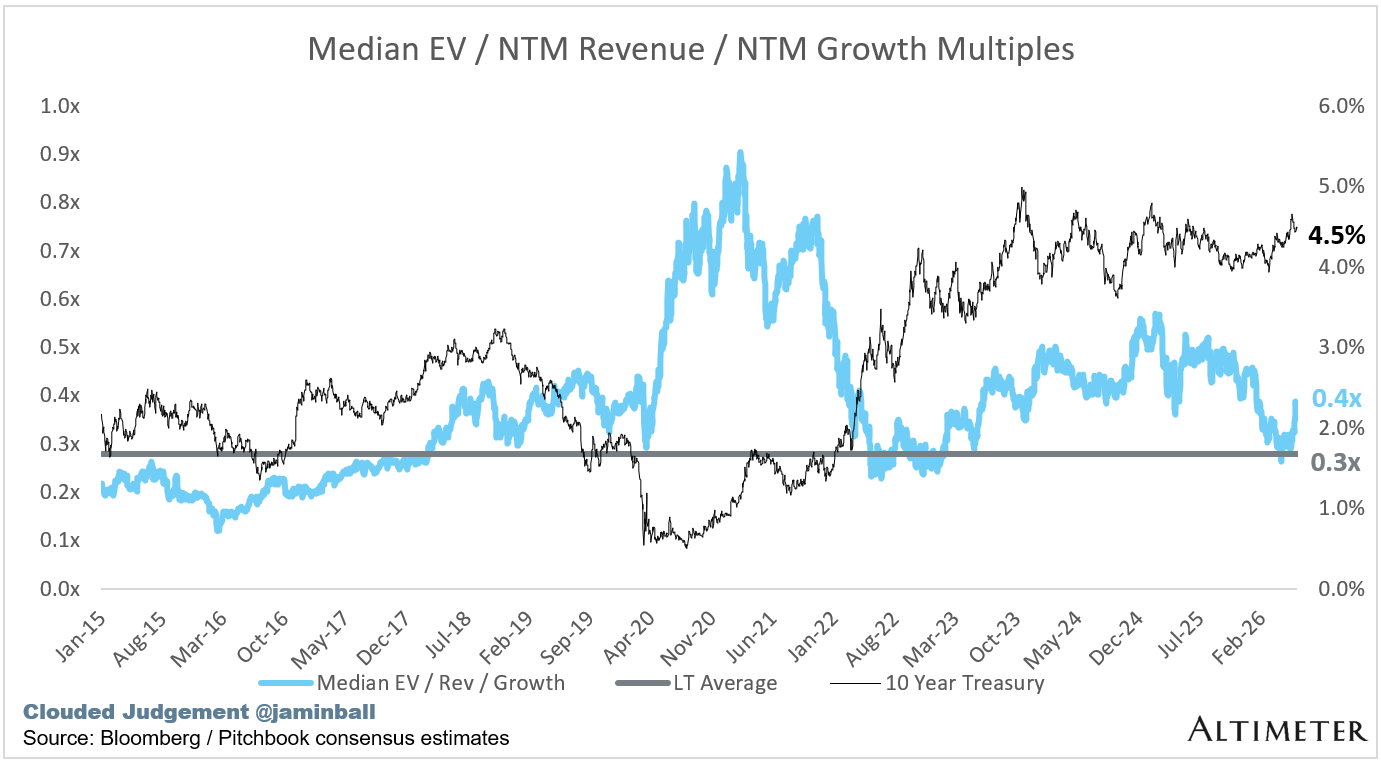
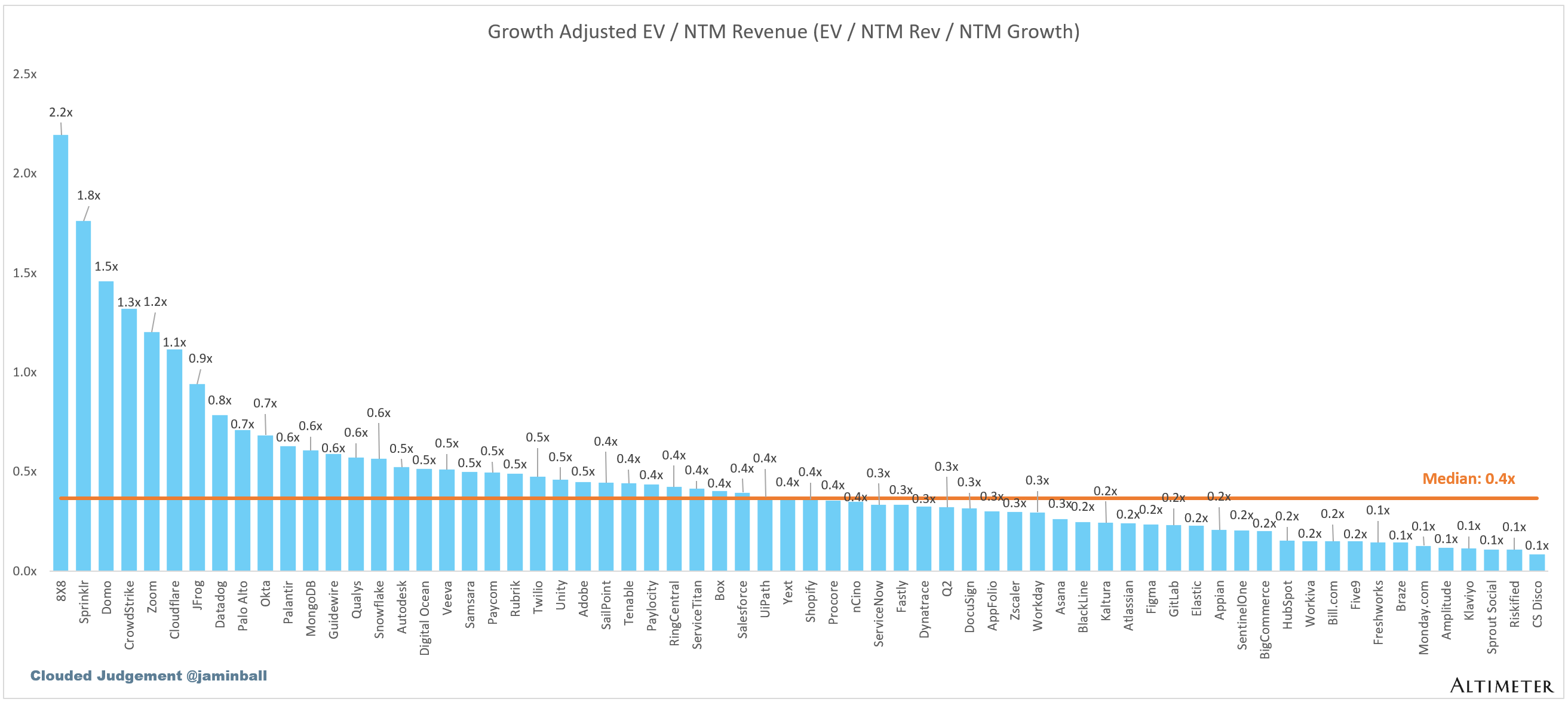
EV / NTM Rev / NTM Growth
The below chart shows the EV / NTM revenue multiple divided by NTM consensus growth expectations. So a company trading at 20x NTM revenue that is projected to grow 100% would be trading at 0.2x. The goal of this graph is to show how relatively cheap / expensive each stock is relative to its growth expectations.
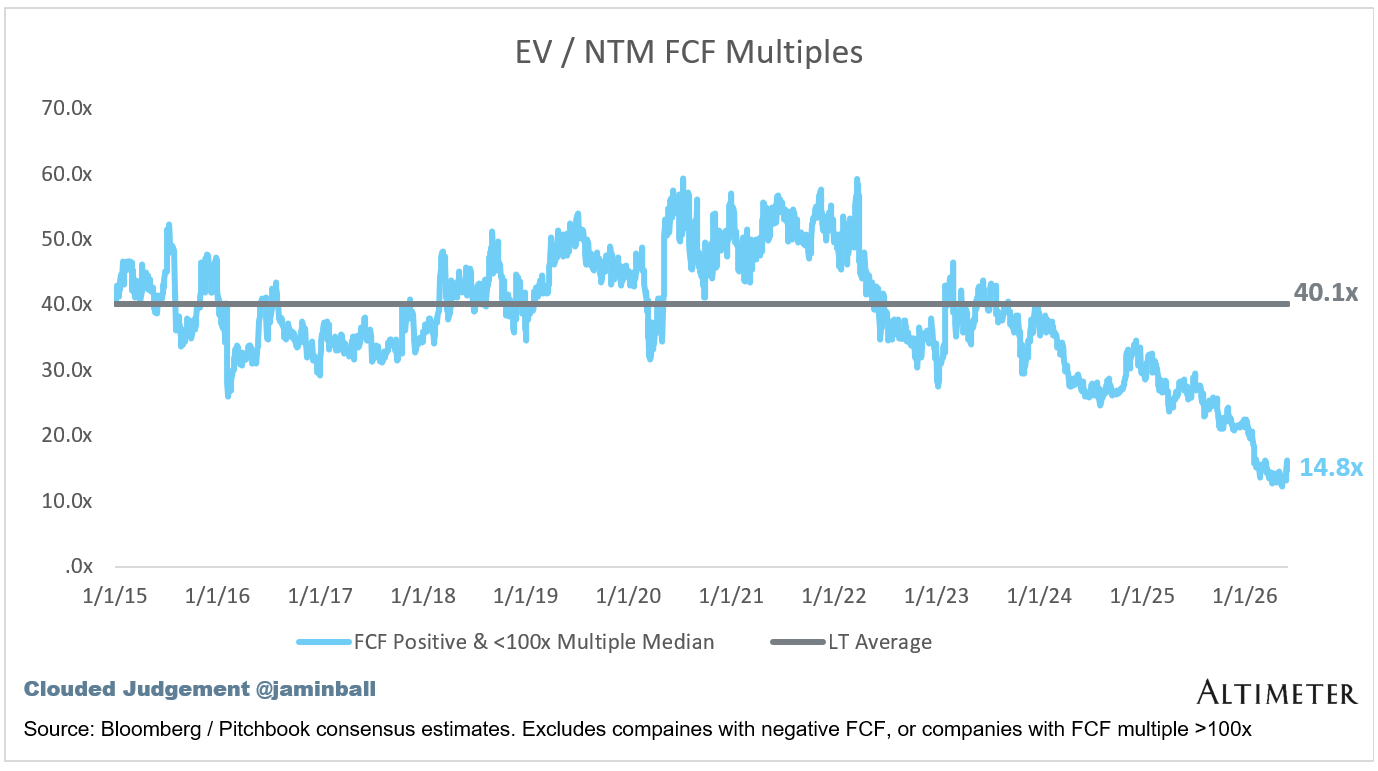
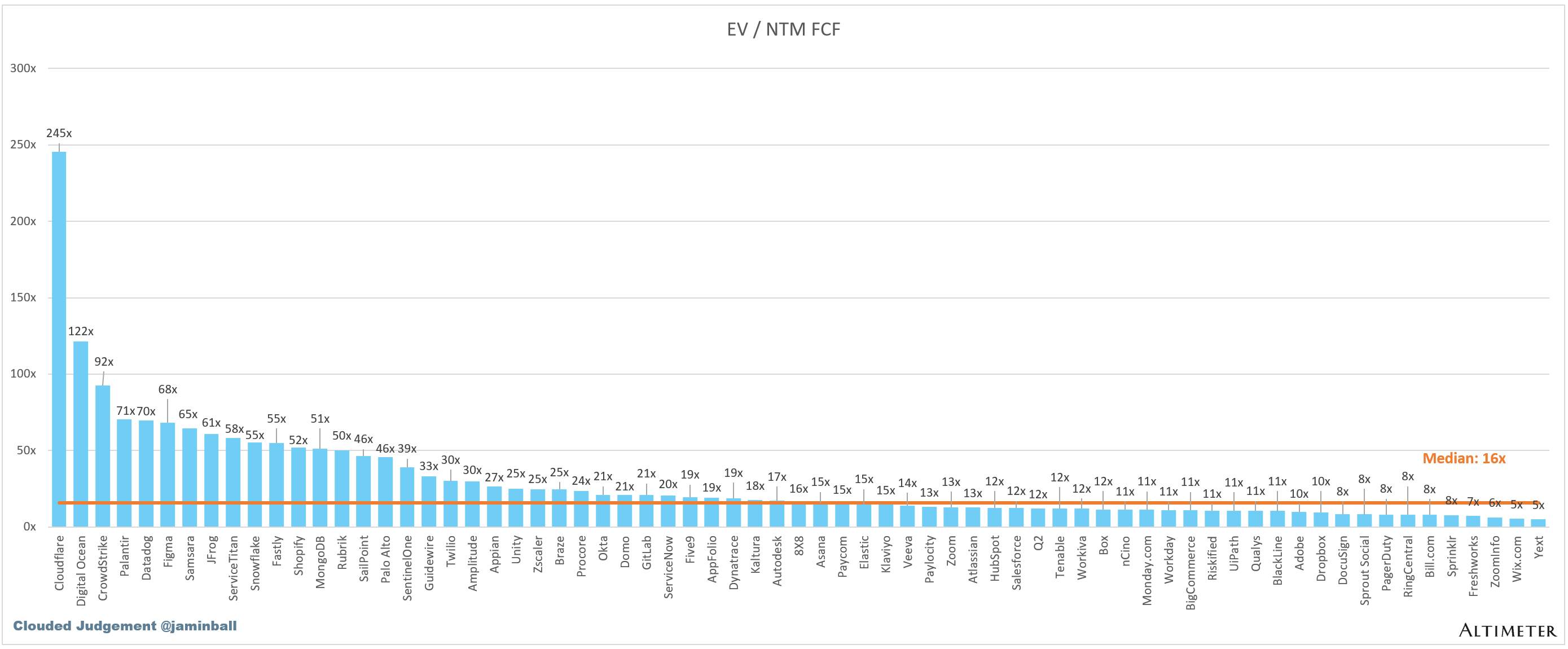
EV / NTM FCF
The line chart shows the median of all companies with a FCF multiple >0x and <100x. I created this subset to show companies where FCF is a relevant valuation metric.
Companies with negative NTM FCF are not listed on the chart
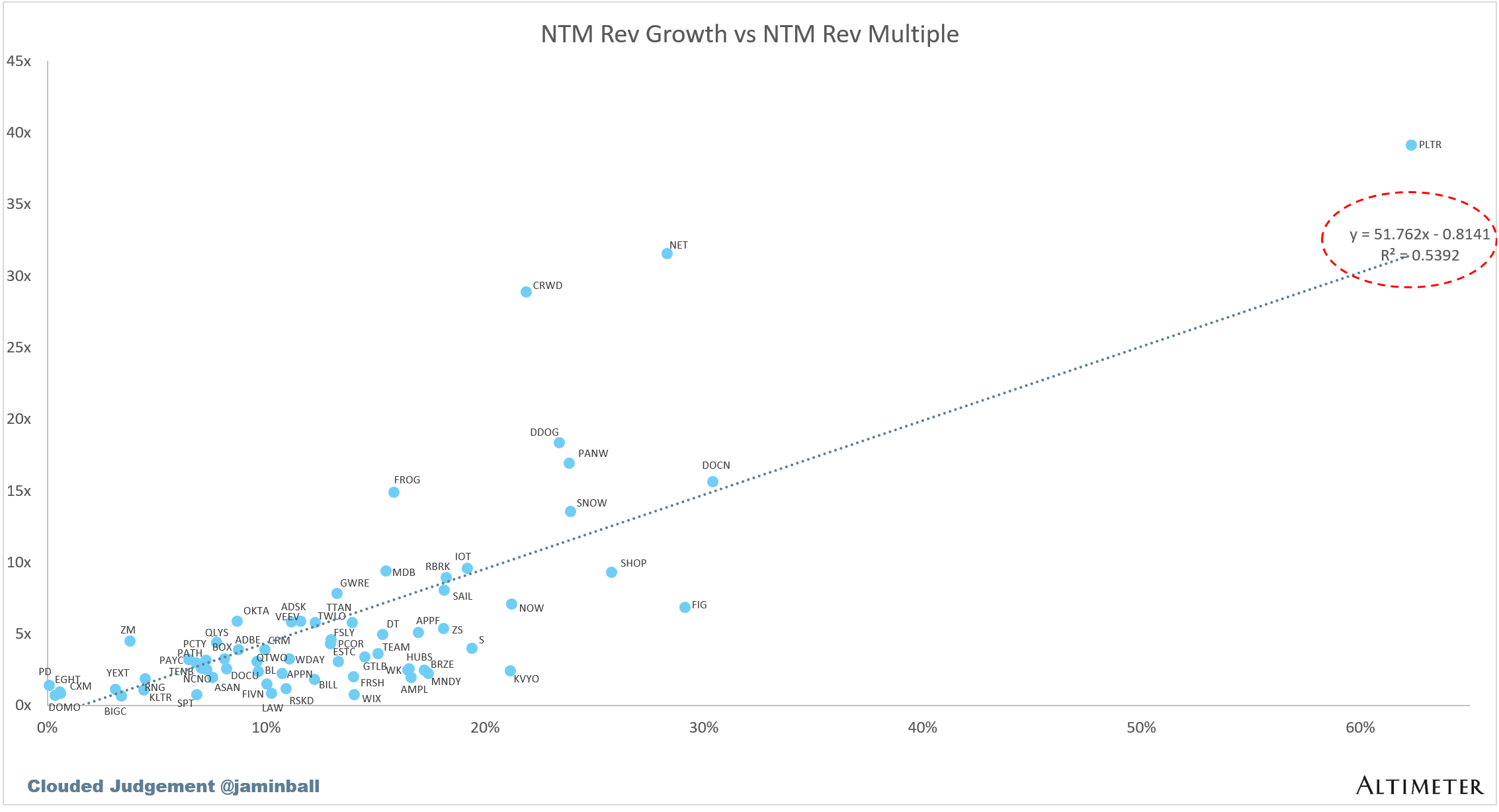
Scatter Plot of EV / NTM Rev Multiple vs NTM Rev Growth
How correlated is growth to valuation multiple?
Operating Metrics
Median NTM growth rate: 12%
Median LTM growth rate: 16%
Median Gross Margin: 76%
Median Operating Margin 2%
Median FCF Margin: 21%
Median Net Retention: 110%
Median CAC Payback: 42 months
Median S&M % Revenue: 34%
Median R&D % Revenue: 23%
Median G&A % Revenue: 13%
Comps Output
Rule of 40 shows rev growth + FCF margin (both LTM and NTM for growth + margins). FCF calculated as Cash Flow from Operations - Capital Expenditures
GM Adjusted Payback is calculated as: (Previous Q S&M) / (Net New ARR in Q x Gross Margin) x 12. It shows the number of months it takes for a SaaS business to pay back its fully burdened CAC on a gross profit basis. Most public companies don’t report net new ARR, so I’m taking an implied ARR metric (quarterly subscription revenue x 4). Net new ARR is simply the ARR of the current quarter, minus the ARR of the previous quarter. Companies that do not disclose subscription rev have been left out of the analysis and are listed as NA.
Sources used in this post include Bloomberg, Pitchbook and company filings
The information presented in this newsletter is the opinion of the author and does not necessarily reflect the view of any other person or entity, including Altimeter Capital Management, LP (”Altimeter”). The information provided is believed to be from reliable sources but no liability is accepted for any inaccuracies. This is for information purposes and should not be construed as an investment recommendation. Past performance is no guarantee of future performance. Altimeter is an investment adviser registered with the U.S. Securities and Exchange Commission. Registration does not imply a certain level of skill or training. Altimeter and its clients trade in public securities and have made and/or may make investments in or investment decisions relating to the companies referenced herein. The views expressed herein are those of the author and not of Altimeter or its clients, which reserve the right to make investment decisions or engage in trading activity that would be (or could be construed as) consistent and/or inconsistent with the views expressed herein.
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.
Jamin, I wonder if open source may be inheriting more assumptions from the frontier labs than we realize.
The article focuses on research breakthroughs, model quality, and the widening gap between frontier and open models. Those are obviously important. But historically, technologies don't always gain traction because they become technically superior. Sometimes they gain traction because someone discovers the application that makes their value obvious.
The early web is an interesting example. By modern standards, PizzaNet was primitive. Yet it pointed almost directly at the future internet economy because people immediately understood what the technology was for.
It makes me wonder whether the biggest opportunity for open source is not necessarily to match the frontier models first, but to discover a commercially compelling use case that the frontier labs are overlooking. If that happened, the ecosystem and funding incentives could look very different very quickly.
Incentives rule. As Charlie Munger said: "Show me the incentives and I will show you the outcome." One potential dis-incentive here is the growing cost of compute. Without Moore's Law exponentially lowering costs for us, we now have to actually pay for the compute we use and that bill is getting big enough to dis-incentivize this type of open source risk taking.