
The Modern Data Cloud: Warehouse vs Lakehouse
Another Data Trend I'm Watching This Year


An interesting data platform battle is brewing that will play out over the next 5-10 years: The Data Warehouse vs the Data Lakehouse, and the race to create the data cloud. Who's the biggest threat to Snowflake? I think it's Databricks, not AWS Redshift, Google BigQuery, or another cloud data warehouse.
What I find most interesting about these two approaches (the warehouse vs the lakehouse), is that they're actually doing something very similar. It's 2 different entry points for the same ultimate vision: to be the data cloud platform. Before getting into the merits / shortcomings of each architecture, let's first define them (in overly simplified terms). Historically the OLD (pre cloud Data warehouse) data architecture was: data > ETL > Warehouse > BI / Analytics (excuse my basic graphics "skills")

As the data collected (in both structured and unstructured formats) skyrocketed, and as data science / ML workloads arose, a two tiered architecture emerged: the warehouse on top of a "data lake." The data lake's purpose was to store all raw data, then "serve up" data for access. Tools like Spark (Databricks) emerged to handle data processing for ML / Data Science workloads
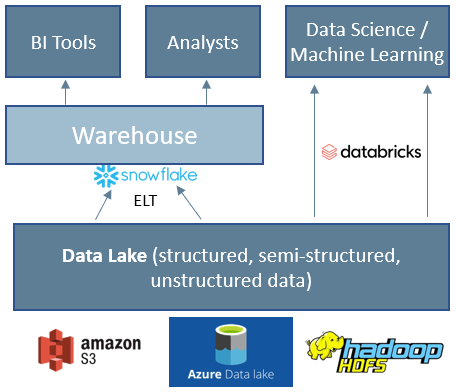
In this version of the world Snowflake (the warehouse) held data that was transformed and ready for efficient access for analytical workloads. Databricks was the data processing engine for data science and machine learning. And underneath both sat the raw storage of all data. As Snowflake moves to become the all encompassing data cloud their first step is blurring the lines between the warehouse and lake, and having customers send ALL their data to the warehouse. I get into the merits of this modern data stack this article. It seems inevitable that Snowflake will move into more of the data science realm. The first phase of their data cloud might look something like this:
Conversely, Databricks has taken the "Lakehouse" approach (data lake at the center, not data warehouse). You might be thinking, "Databricks doesn't have a storage layer?" While that may have been true historically, times are changing with the rise of the Delta Lake technology. IMO Delta Lake is super powerful.
Delta Lake is a new open source standard for building data lakes. It brings the best functionality of the warehouse into the lake (structured tables, reliability, quality, performance). Think of it as data tables in your lake. And converting from parquet to delta lake is simple. In Databricks’s paper on the Lakehouse architecture they describe it as:
“a transactional metadata layer on top of the object store that defines which objects are part of a table version. This allows the system to implement management features such as ACID transactions or versioning within the metadata layer, while keeping the bulk of the data in the low-cost object store and allowing clients to directly read objects from this store using a standard file format in most cases.”
It's like a warehouse within the lake. Here's how Databricks see's the world: They say to the customer, keep your data in your own managed lake / object store (S3, ADLS, HDFS, etc). We'll then provide a managed Delta Lake experience on top. Above the Delta Lake you can still do the data processing with Spark / DataFrames for ML/data science, and then we'll offer our own query engine (Delta Engine) to allow BI analysts / businesses analysts to access data with SQL (SQL access is important).
The SQL access to data lake storage is huge. It's a market we're seeing Dremio and Starburst go after. The reason these tools emerged is to offer direct SQL access to raw / object storage. This is hard to do. I hope I didn't loose folks. In summary Databricks will offer a Delta Lake within the lake and then allow SQL access to data for BI (through their Delta Engine), and processing / data prep for data science / ML (through Spark + DataFrame APIs). It might look something like this:

The Databricks team put together a thoughtful paper here outlining their approach that can be found here
We've arrived to the two approaches
Snowflake Data Cloud (Warehouse center)
Databricks Data Cloud (Delta Lake Lakehouse center)
I have no doubt that eventually both Snowflake and Databricks want to move up into the BI / ML world making the ULTIMATE data clouds look like this:

What are advantages / disadvantages of both?
With Snowflake - It's so easy to use. Compute / storage scale independently, and the tools around it (like Fivetran, dbt) make it easy to get data in and then transformed. Ultimately it's incredibly performant and powerful. The downsides? In the interim, managing a two tiered architecture (warehouse + lake) can be challenging (maintaining consistency). In it's end state (no lake), it can be very expensive. I'd love to see Snowflake find a way to better separate / charge for cold storage.
Moving on to the Databricks / Lakehouse approach. It's much cheaper (especially w/real scale) and you only have to worry about one storage layer (the data lakehouse). The combo of delta lake + delta engine (or something like Presto) is a great alternative to the cost of Snowflake. Challenges? Databricks is so centered around Spark. Can they move into BI? And do you really need direct SQL access to the raw lake data? What uses cases does direct access to parquet files enable? IMO the idea of centralized storage for all data is organizationally challenging. Of course, there's always the middle ground. I think there will always be uses cases for lakes and warehouses to sit alongside each other (two tiered), and that might end up being the best approach.
Many thanks to Bryan Offutt and Matt Slotnick for indulging me over the weekend to chat about data architectures. Lots of this thread was inspired by conversations I had with them. Just the standard stuff we choose to talk about in our free time :)
I think you may have a fundamental misunderstanding for the value Snowflake brings to the Data Lake use case. There is a reason why Snowflake no longer calls itself a "Cloud Data Warehouse" because that term is overloaded and can confuse people about the workloads Snowflake can take on. Some the earliest and largest Snowflake wins were really Data Lake use cases. Companies with massive amount of semi-structured files struggled to query them at scale using Hadoop, and Snowflake came along and made it easy. If you have a million JSON or Parquet files and want to query them performantly with SQL, name a better technology than Snowflake to do that today. I'd frame the difference as Snowflake allows you to meet Data Lake and Data Warehouse use cases in the SAME TECHNOLOGY. Using SQL. Without having to create indexes or do performance tuning. The only difference is, Snowflake gleans statistics about the files as it ingests them so you can query the files as is. Describing this as "two tiers" is fundamentally inaccurate--there is no logical difference for a company "loading" a semi-structured file into a "Data Lake" and loading that same exact file into a Snowflake managed data lake. None. In the US pricing is $20-$23/compressed TB on contract depending on your Cloud provider, and compression is excellent, so you get a reasonable storage price while still being able to query ANY of your data at speed.
Beyond that, even if you DIDN'T want to load the data into Snowflake for some reason, and you DID want to maintain a "two-tier" architecture, Snowflake offers a host of features (external tables, streams on external tables, materialized views on top of external tables, etc.) that can provide usability and performance even in that case. Now that Snowflake can load unstructured data (the feature is in preview, but announced), there aren't many data lake use cases that Snowflake can't handle in a world-class way.
Love the coverage on the data space! Curious what you meant by "I'd love to see Snowflake find a way to better separate / charge for cold storage." as snowflake stores data on S3 and the cost is the same. The bulk of the cost ends up coming from compute which is the key piece to scaling out large data infrastructures with many analytical transformations. Where I've seen storage become a little more expensive is if you choose to store your data in a data lake before moving to snowflake. You then double your storage cost with the redundancy, but S3 storage is relatively cheap. Either way it is awesome to see where both companies are moving. It would be awesome to get to where both data science and BI/analytics can be powered by a single (ware/lake)house rather than needing to have one for each.