
Clouded Judgement 10.17.25 - From Data Quantity to Data Quality

Every week I’ll provide updates on the latest trends in cloud software companies. Follow along to stay up to date!
From Data Quantity to Data Quality
A few weeks ago I wrote a post titled “The New RL Training Grounds.” I wanted to write a follow up post to that one, as this continues to be an area I’m quite excited about.
If we look back over the last few years there are pretty clear patterns of “hot topic debates” that seem to pop back up every so often around AI. One I want to discuss today is the broad topic of “will scaling laws hold.”
It’s a nuanced question, because “scaling laws” really mean many things, all of which trace back to data and compute. The debate was broadly could you keep throwing more data and compute at the models to make them better, or would they start to plateau. Over time, nuance has emerged. It’s not just about watching performance scale with more data / compute, but watching performance scale based on where / when / what type of data / compute you throw at models to make them better. Regardless of the nuance, the debate seems to perpetually oscillate between “they wont hold!” to “they will hold!” And this repeats itself…
Early on in model development, large corpuses of data were used in the pre-training phase - essentially teaching the model language and general world knowledge by exposing it to massive amounts of internet text, code, and images so it could learn basic patterns before being fine-tuned for specific tasks. One of the more notable debates around scaling laws emerged when Ilya Sutskever (an OpenAI co-founder and now co-founder of SSI) gave a talk at NeurIPS in 2024. In this talk, he essentially proclaimed that we’d hit a “peak data” moment in the industry. He compared the internet’s finite, human-generated content to a fossil fuel source for AI. He contended that major AI labs had already consumed most of the available, useful data for training models, and there simply wasn’t anything left! Well, if there was no more data left to throw at models, then one side of the compute / data scaling laws equation appeared to be breaking.
Then we had debates around compute scaling laws. DeepSeek launching a model (and claiming to have only spent a couple million dollars to build a state-of-the-art model) launched a new wave of “will compute scaling laws hold.”
Fast forward to today, and there’s been a few key developments around both data and compute scaling laws. On the compute side, entirely new vectors of compute scaling have emerged. OpenAI released their O-series of models (their reasoning models) which essentially trade raw parameter count for more intensive, iterative compute. Models that think longer, not just bigger, using additional inference-time computation to improve reasoning and accuracy. Said another way, instead of throwing more compute during pre-training to make models better, you could throw more compute at them at inference time to make them better. And viola, a new compute scaling law emerged!
Which then leads me to data scaling laws (and the new vector of data scaling laws that have emerged). It’s hard to argue (at it’s surface) for the argument Ilya made at NuerIPS back in 2024. At the end of the day - he wasn’t wrong! Once you’ve exhausted all of the internets data, there’s nothing left… HOWEVER - not all knowledge is stored on the internet. There are huge corpuses of data sitting in knowledge workers heads. Call this tribal knowledge, institutional knowledge, best practice knowledge, etc. It’s knowledge that is less binary in nature. It’s data that’s less of a “single turn” set, and instead more multi-turn set - meaning it captures the back-and-forth of reasoning, explanation, and iteration that happens when experts think through complex problems, providing context, reflection, and justification rather than just an answer.
This data is often described as “phd or masters level” data, and it’s often very domain specific. Not only do you need the data, but you need the end state of that data, and a “this was right” or “this was wrong” tag. Let’s take a look at one domain of models that have taken off - coding. Why is it that coding has taken off? One reason is the data is very structured, with a clear “this worked” or “this didn’t". Code can be complex - many lines of code, nested functions, etc. But at the end of the day, you can have a series of tests you run on that code to know if “it worked.” Did it compile, did it pass the unit tests, did it return the correct API response, did it handle edge cases without throwing errors, etc. With code, there was also an abundance of “code data” sitting in open source repositories. Side note - on top of getting data from open source libraries, it wasn’t uncommon for the large AI labs to “acquire” failed startups not for their talent, not for the IP, but for the raw code base. Not sure what to call these - it’s the equivalent of an acquihire (for talent) but for data. Datahire?
Other domains don’t have that same clarity. In medicine, you might know whether a treatment helped a patient, but not exactly why it did. In law, two experts might reason differently and still reach valid interpretations. In finance, a trade might make money, but it’s hard to isolate whether it was skill, timing, or luck.
And this brings us to the next data scaling laws - compiling ALL of this data / knowledge in domain specific fields like medicine, law, finance, etc. If an investment banker is given two public companies, how do they go create a merger model? If a lawyer is given a complex contract, how do they identify risks, negotiate clauses, and redline terms? If a doctor is presented with a patient’s symptoms, how do they reason through differential diagnoses and treatment plans? If an engineer is tasked with optimizing a semiconductor layout, how do they balance performance, yield, and thermal constraints? Each of these workflows represents domain-specific expertise that can’t be captured by static text. They require reasoning, iteration, and feedback, the foundation for the next generation of data scaling laws.
And the market for “frontier data” is EXPLODING! ALL of the major labs are fighting hand over fist to acquire more domain specific data. It’s never been so obvious to me that we are in the early innings of this new data scaling law. Recruiters who once placed finance professionals into junior investment banking or private equity roles are now placing them into AI labs or into firms like Mercor, Handshake (or younger companies like AfterQuery) so that their knowledge can be incorporated into the next set of AI models (we’re giving the models data to replace ourselves!). The market for part time “data labeling” of domain specific knowledge is exploding.
And unlike generation 1 of data labeling (think “is this a cat or a dog” type labeling), HOW we collect this data is non trivial. Labeling an image is easy. How do you label “the process of red-lining a legal contract.” Do you screen record for a computer use model? Does a lawyer dictate what they’re thinking as they’re marking up the contract? There are so many possibilities. But how that data collection is scaled and captured is non trivial. I think there will be a lot of companies who create significant value solving these problems. And then, there are entirely new sets of data to collect. Take a company like David.ai who recently announced a fundraise. They are providing companies with audio data sets to train audio models. There will be many other domain specific (or type specific) dataset companies.
This post was a brain dump…But I wanted to conclude with my takeaway. One thing I can say for certain - the “scaling laws” debates will continue to rage on forever. Sometime down the road we’ll start to debate whether we’ve hit the end of the road of inference time compute scaling. We’ll also eventually debate whether we’ve exhausted all the “domain specific PHD level data.” BUT - what I can also say with near certainty, is just like the early pre-training compute scaling laws and pre-training internet data labeling scaling laws gave way to inference time compute scaling laws and domain specific PHD data scaling laws (more of the RL stuff), there will be more vectors of both compute and data scaling laws that come AFTER the inference time compute and PHD level data scaling laws. The progress and innovation on research and algorithms has been staggering, and I think we’re just getting started!
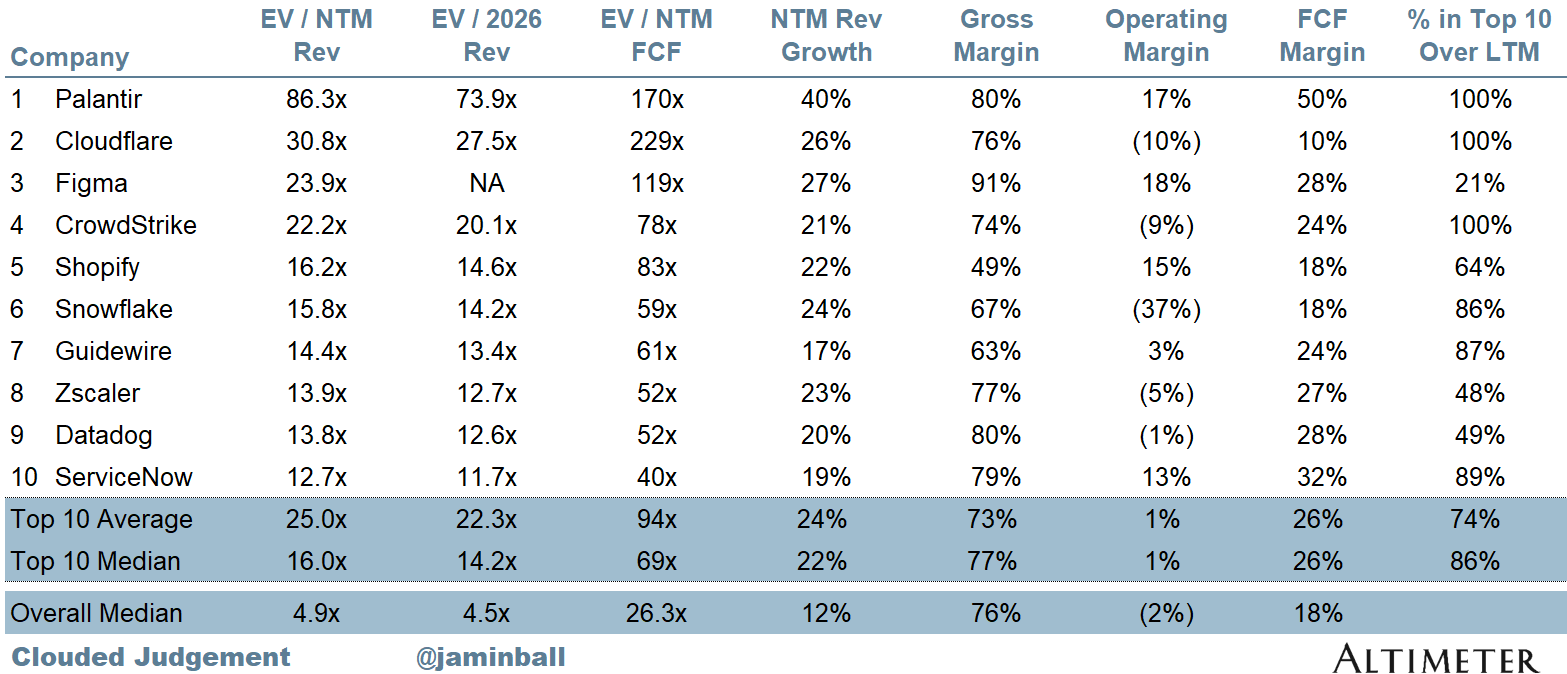
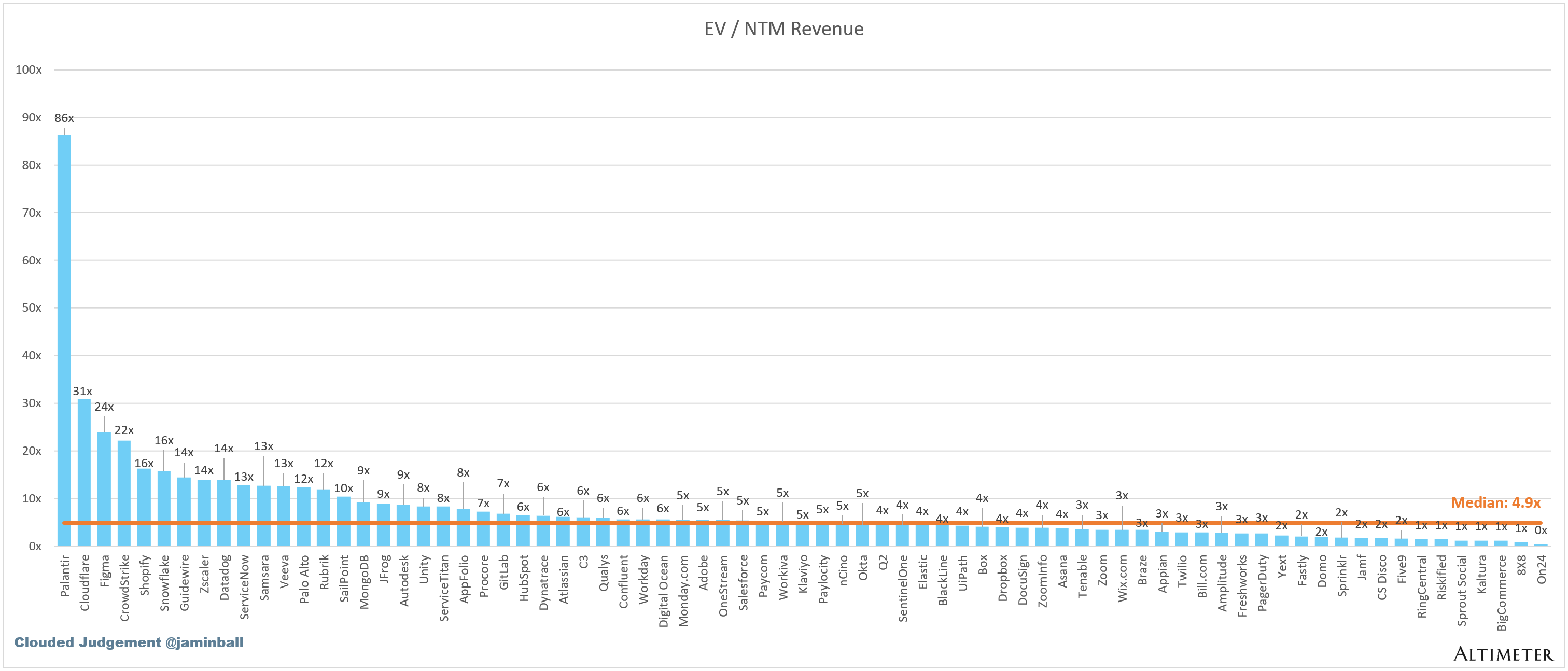
Top 10 EV / NTM Revenue Multiples
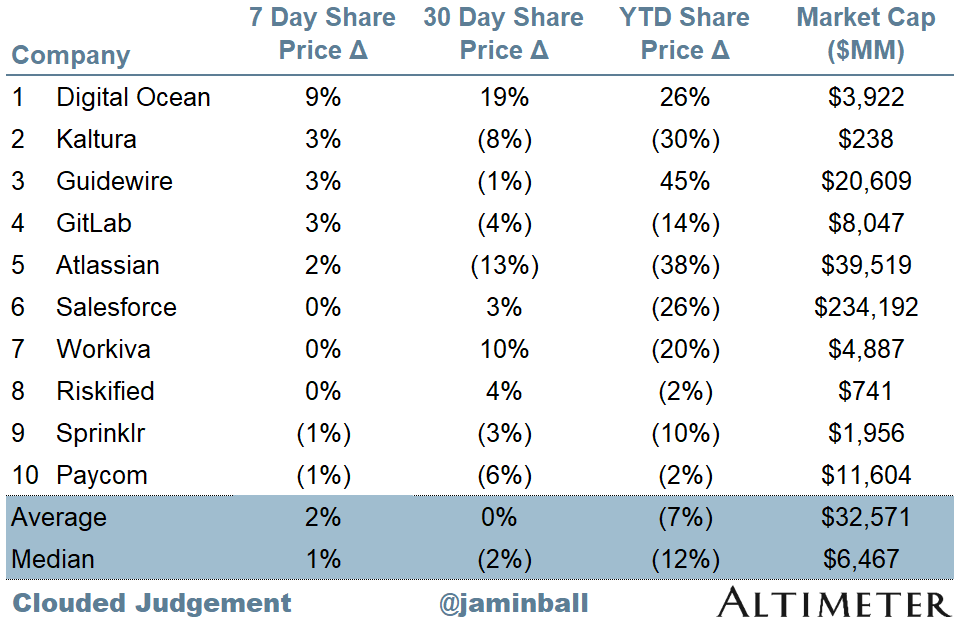
Top 10 Weekly Share Price Movement
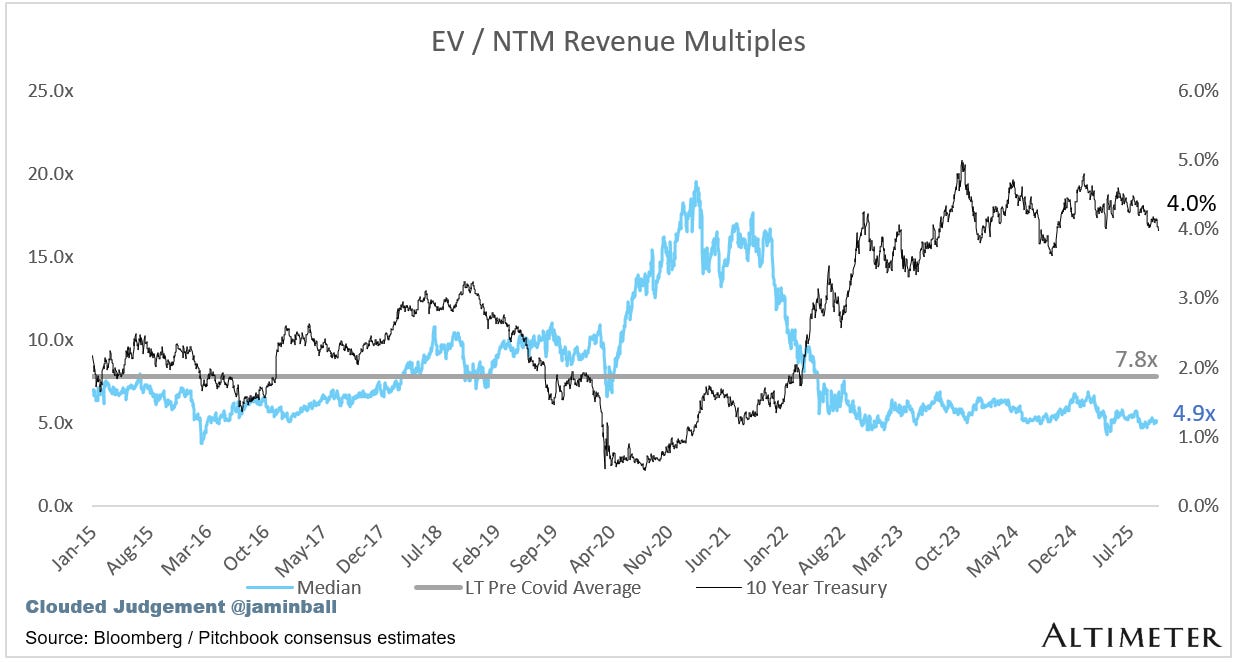
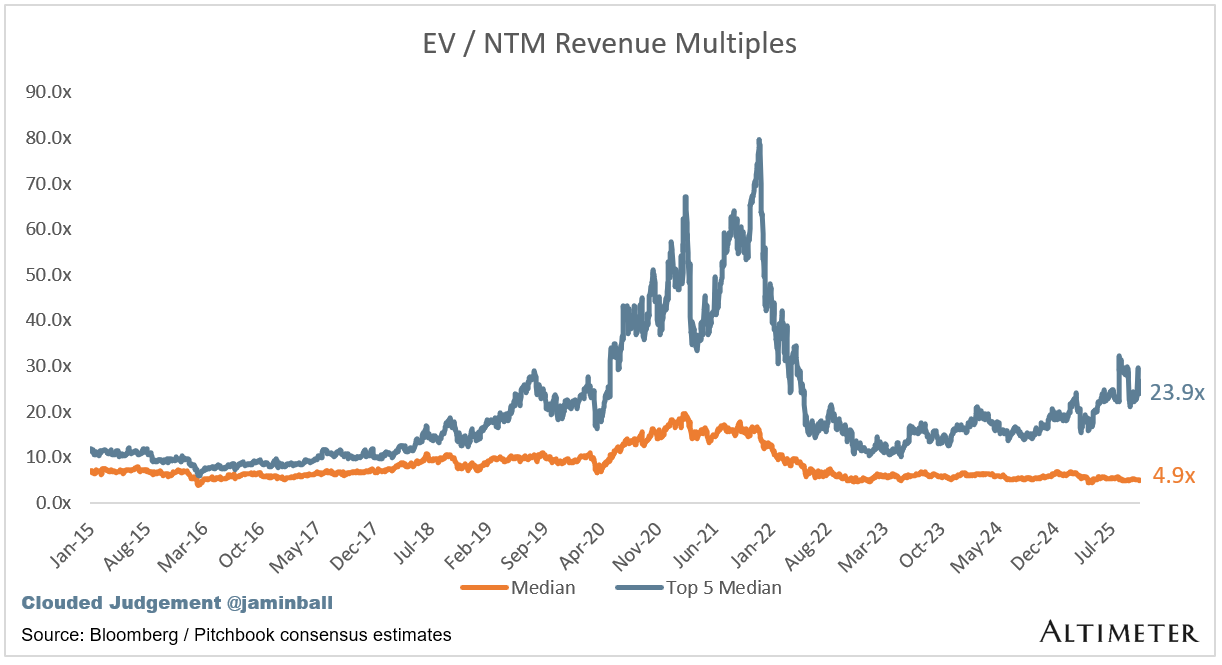
Update on Multiples
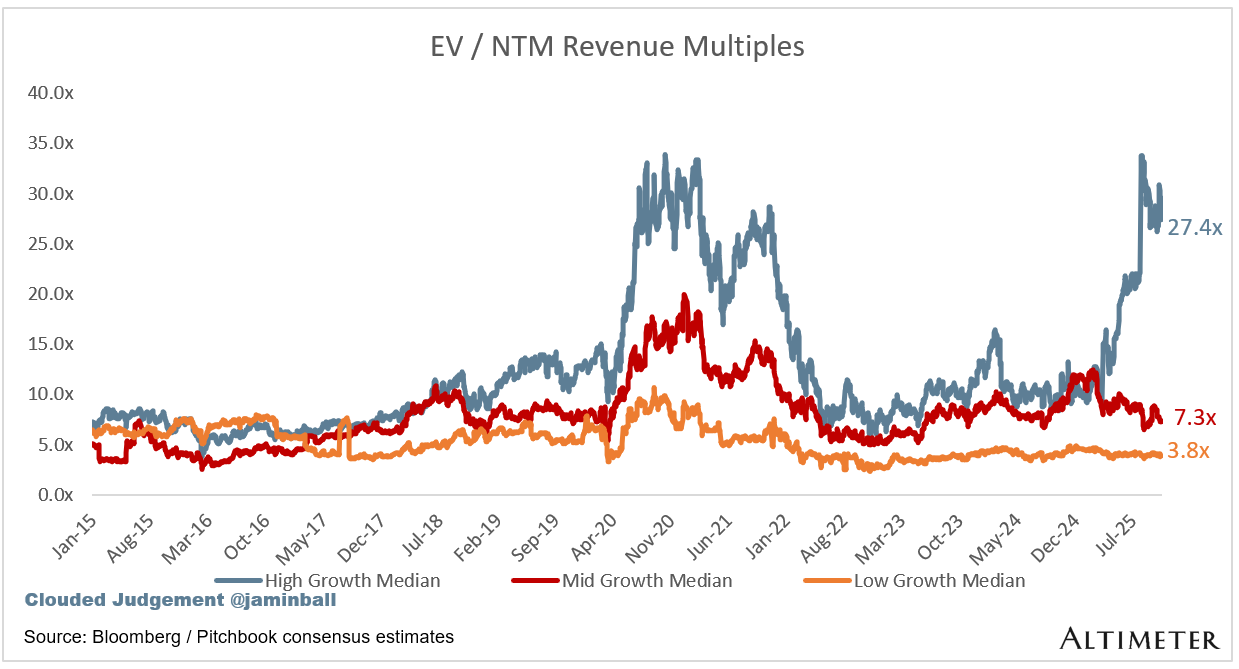
SaaS businesses are generally valued on a multiple of their revenue - in most cases the projected revenue for the next 12 months. Revenue multiples are a shorthand valuation framework. Given most software companies are not profitable, or not generating meaningful FCF, it’s the only metric to compare the entire industry against. Even a DCF is riddled with long term assumptions. The promise of SaaS is that growth in the early years leads to profits in the mature years. Multiples shown below are calculated by taking the Enterprise Value (market cap + debt - cash) / NTM revenue.
Overall Stats:
Overall Median: 4.9x
Top 5 Median: 23.2x
10Y: 4.0%
Bucketed by Growth. In the buckets below I consider high growth >25% projected NTM growth, mid growth 15%-25% and low growth <15%
High Growth Median: 27.4x
Mid Growth Median: 7.3x
Low Growth Median: 3.8x
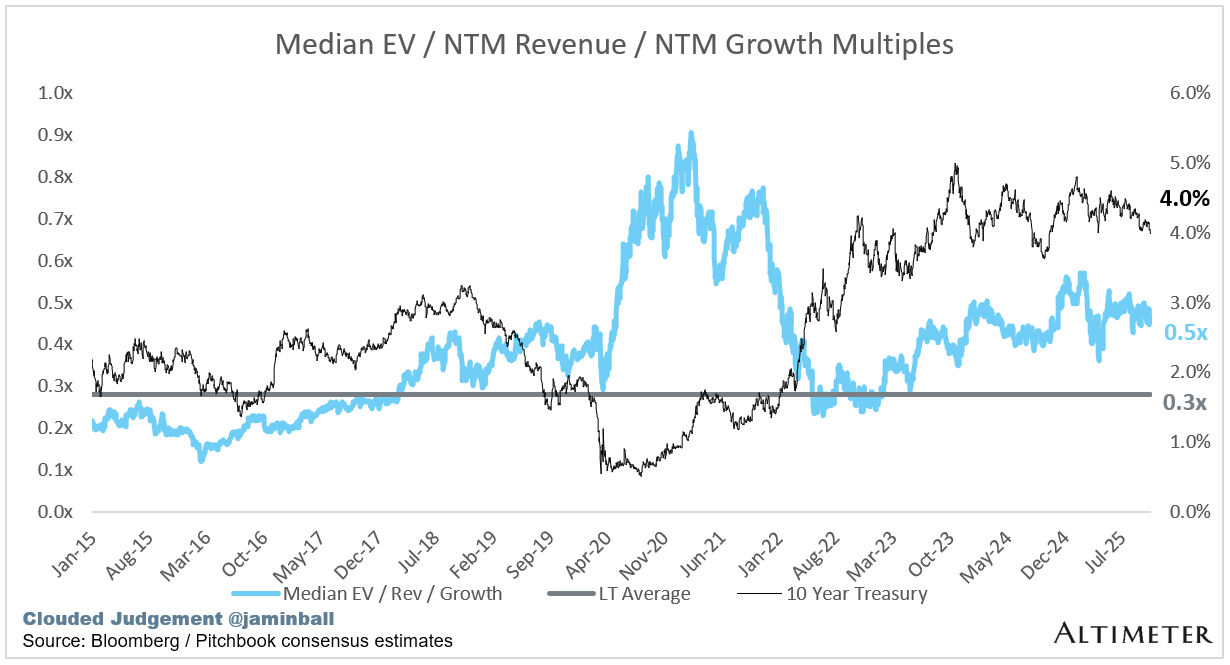
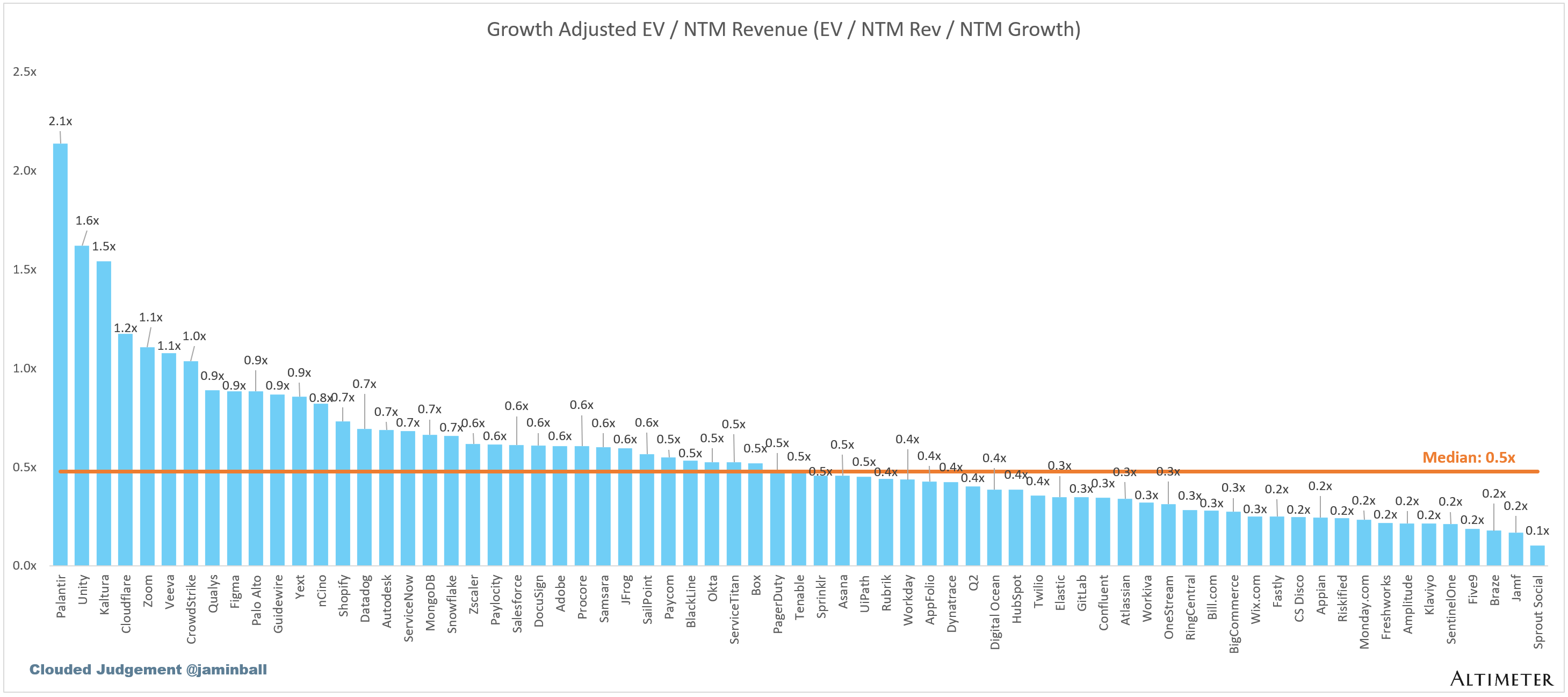
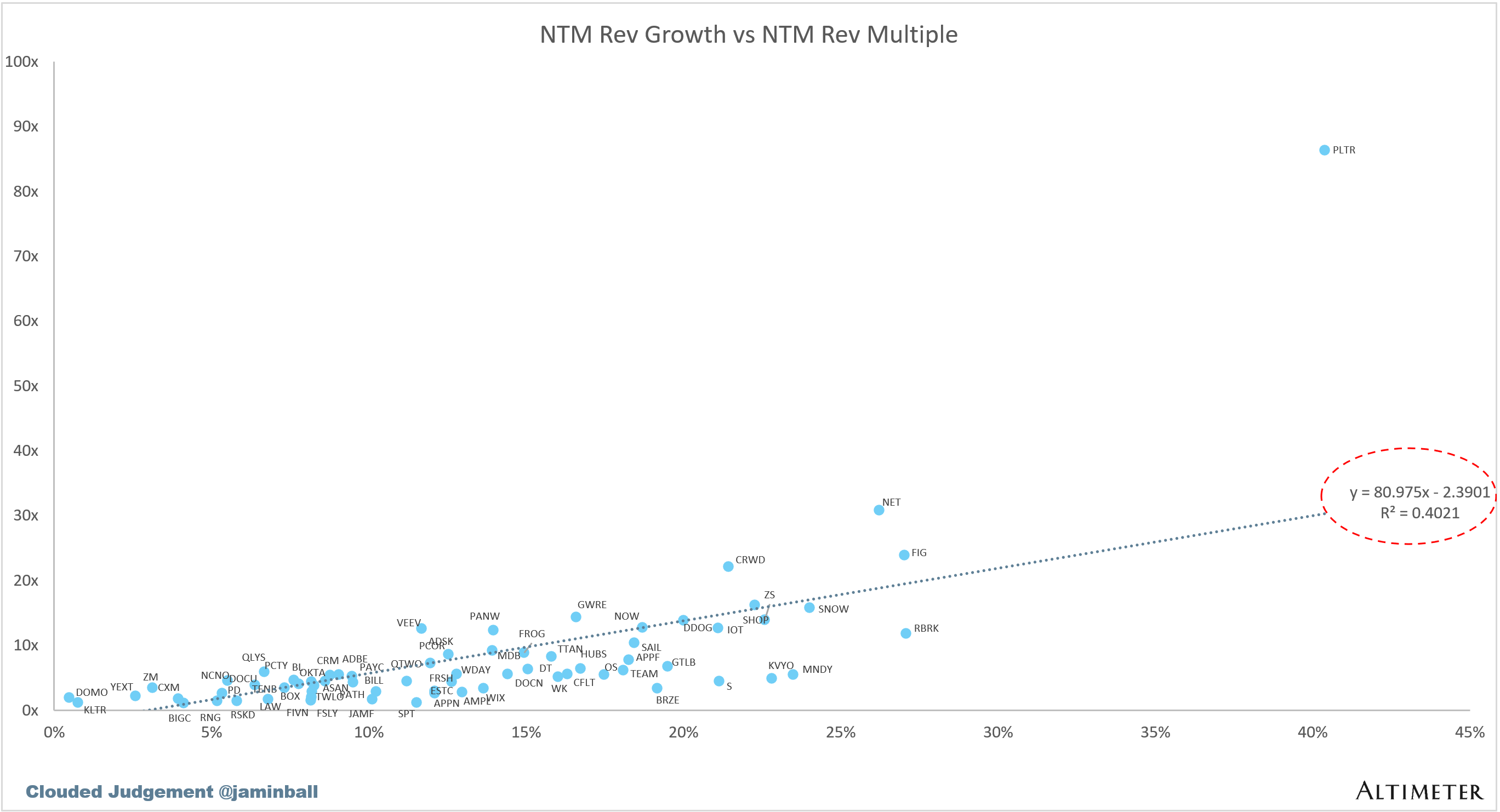
EV / NTM Rev / NTM Growth
The below chart shows the EV / NTM revenue multiple divided by NTM consensus growth expectations. So a company trading at 20x NTM revenue that is projected to grow 100% would be trading at 0.2x. The goal of this graph is to show how relatively cheap / expensive each stock is relative to its growth expectations.
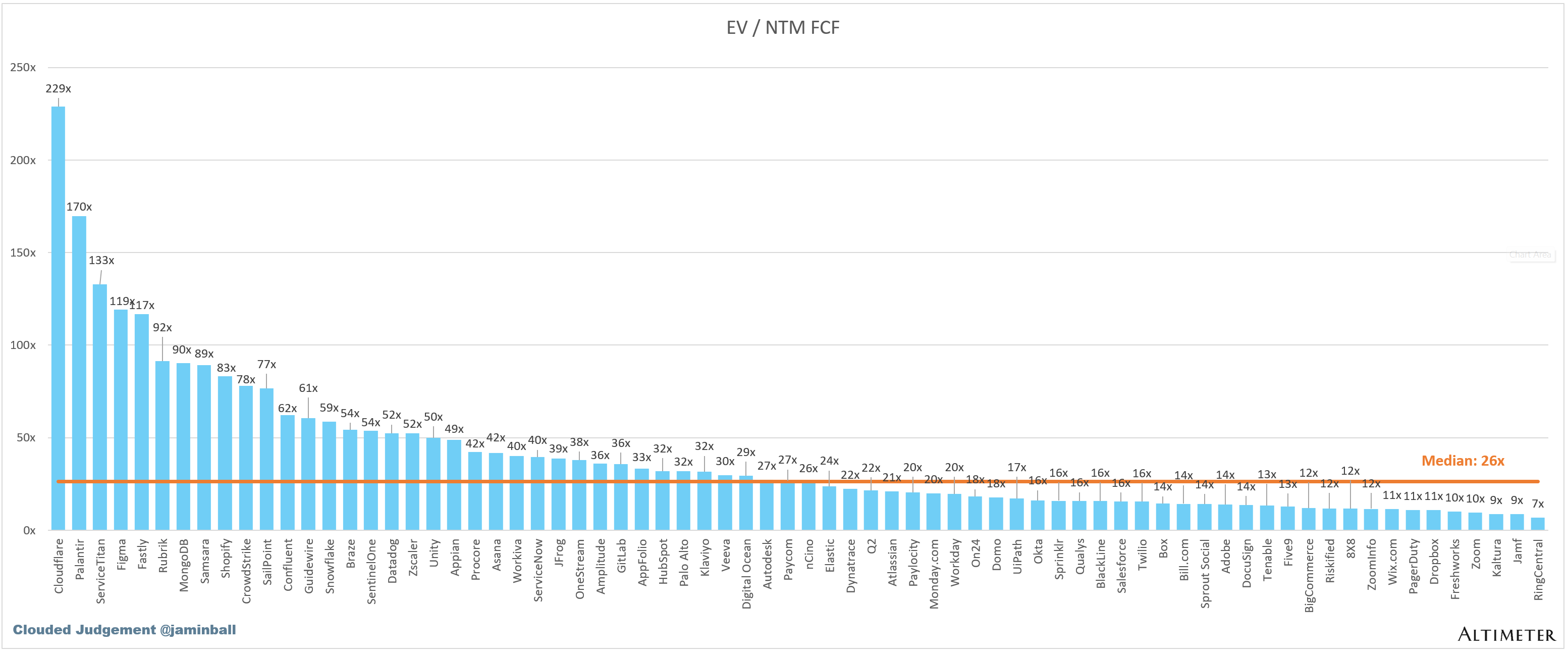
EV / NTM FCF
The line chart shows the median of all companies with a FCF multiple >0x and <100x. I created this subset to show companies where FCF is a relevant valuation metric.
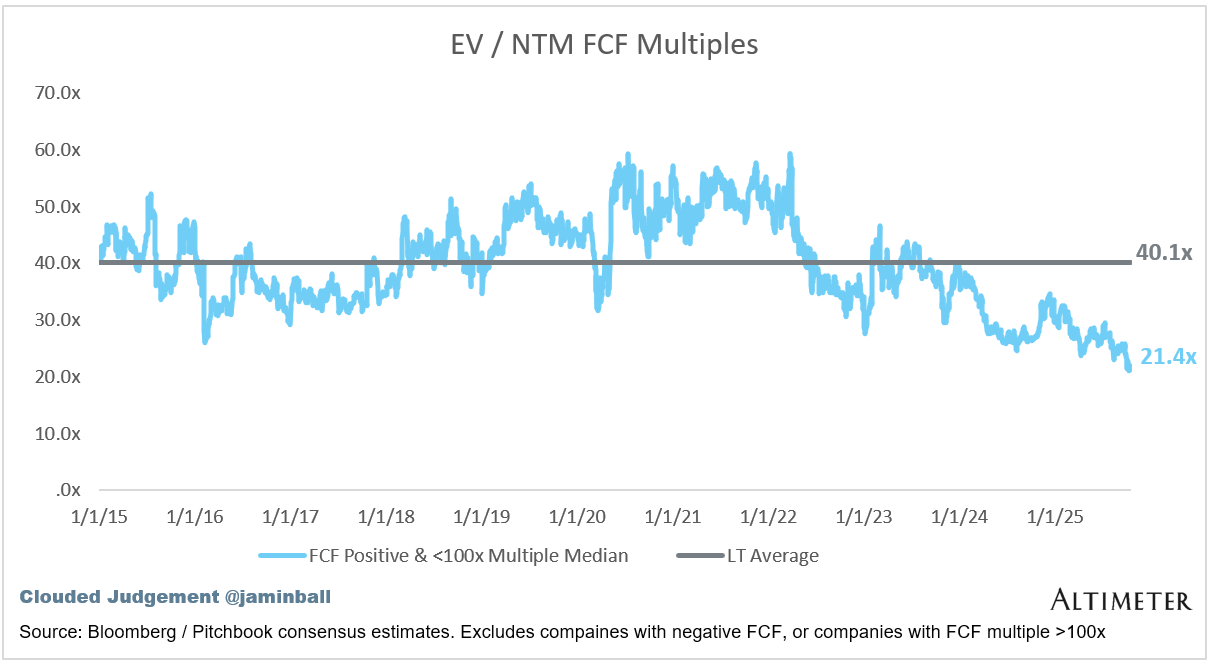
Companies with negative NTM FCF are not listed on the chart
Scatter Plot of EV / NTM Rev Multiple vs NTM Rev Growth
How correlated is growth to valuation multiple?
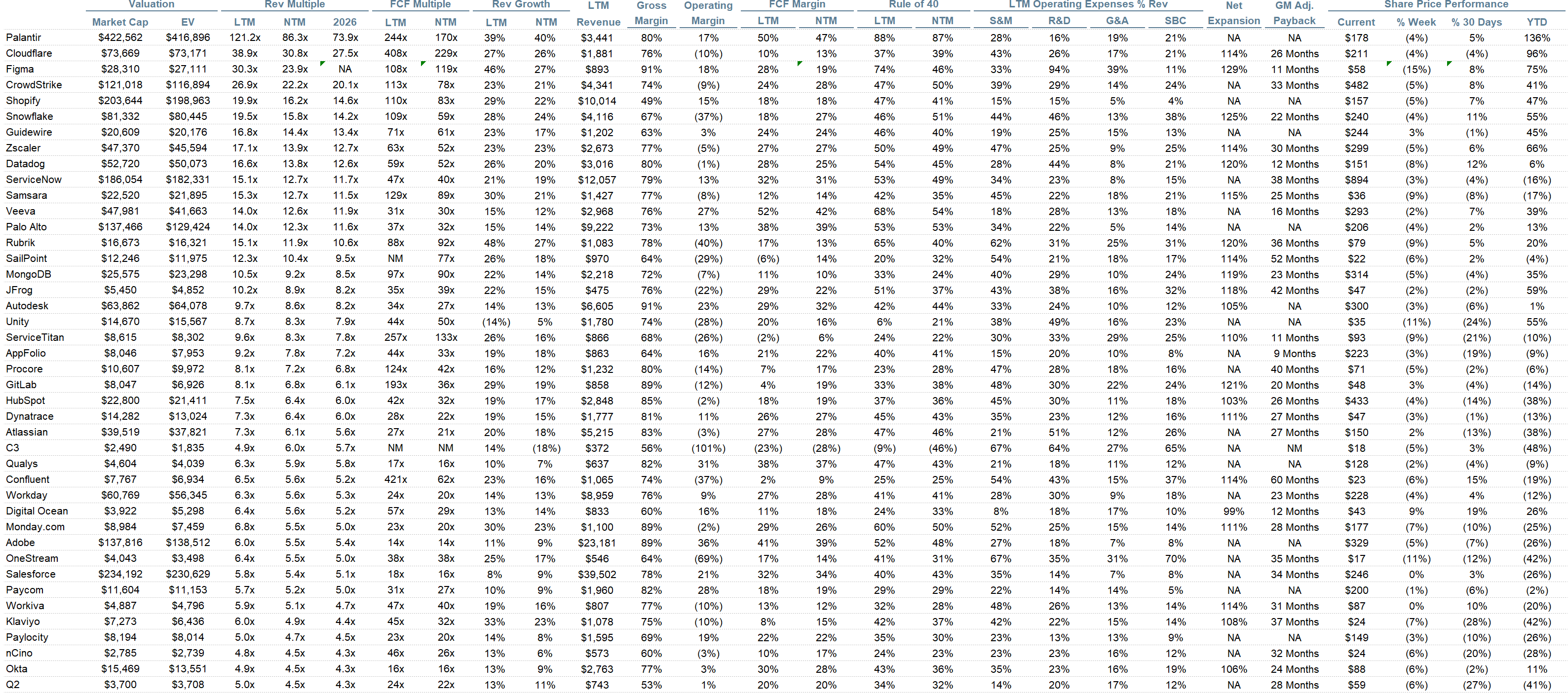
Operating Metrics
Median NTM growth rate: 12%
Median LTM growth rate: 14%
Median Gross Margin: 76%
Median Operating Margin (2%)
Median FCF Margin: 18%
Median Net Retention: 108%
Median CAC Payback: 32 months
Median S&M % Revenue: 37%
Median R&D % Revenue: 24%
Median G&A % Revenue: 15%
Comps Output
Rule of 40 shows rev growth + FCF margin (both LTM and NTM for growth + margins). FCF calculated as Cash Flow from Operations - Capital Expenditures
GM Adjusted Payback is calculated as: (Previous Q S&M) / (Net New ARR in Q x Gross Margin) x 12. It shows the number of months it takes for a SaaS business to pay back its fully burdened CAC on a gross profit basis. Most public companies don’t report net new ARR, so I’m taking an implied ARR metric (quarterly subscription revenue x 4). Net new ARR is simply the ARR of the current quarter, minus the ARR of the previous quarter. Companies that do not disclose subscription rev have been left out of the analysis and are listed as NA.
Sources used in this post include Bloomberg, Pitchbook and company filings
The information presented in this newsletter is the opinion of the author and does not necessarily reflect the view of any other person or entity, including Altimeter Capital Management, LP (”Altimeter”). The information provided is believed to be from reliable sources but no liability is accepted for any inaccuracies. This is for information purposes and should not be construed as an investment recommendation. Past performance is no guarantee of future performance. Altimeter is an investment adviser registered with the U.S. Securities and Exchange Commission. Registration does not imply a certain level of skill or training. Altimeter and its clients trade in public securities and have made and/or may make investments in or investment decisions relating to the companies referenced herein. The views expressed herein are those of the author and not of Altimeter or its clients, which reserve the right to make investment decisions or engage in trading activity that would be (or could be construed as) consistent and/or inconsistent with the views expressed herein.
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update the information or analysis contained herein in the future.
Jamin, thanks, this is a great article about peeking into the future, especially how we are in the reasoning phase. Very well explained how Models are going to capture for reasoning -- the human domain knowledge and experience to think like experts. My background data arch experience at Ivy league also gave a peek in to it but externally it is moving much faster...
This article comes at the perfect time. My Strava data quality debate is real to!