
Tabular: Turning Your Data Swamp into a Data Lakehouse with Apache Iceberg


Please note this is a repost from Altimeter’s LinkedIn. You can find the original post here
Today we’re very excited to announce our partnership and Series B investment in Tabular, a company building around Apache Iceberg. Tabular is a compelling data lakehouse solution, meaning it brings data warehouse functionality (SQL semantics + ease of use) to the data lake (cost-efficient and scalable).
If you want your data platform to run like those at Netflix, Salesforce, Stripe, AirBNB and many others (i.e. object storage + Iceberg), then we believe that Tabular is the right platform for you! Iceberg is one ingredient in the fully packaged Tabular lakehouse.
If you don’t want to manage all of the infrastructure around Iceberg (plus allocating headcount to do this!) but want the benefits of a compelling data lakehouse, then Tabular is the right platform for you.
If you want features in your lakehouse (on top of open source Iceberg) for ingestion, CDC, streaming (file loading, Kafka connect, etc), schema evolution, compaction, optimization, time travel, snapshots, auto-scaling, maintenance (no more writing spark jobs to delete snapshots!), universal access controls (RBAC) or a REST catalog, then we feel that Tabular is the right platform for you!
Before diving into more specifics about what Tabular does, I’d like to start with a brief overview of how cloud-native data architectures have evolved over the last decade. Then I’ll weave in where Tabular / Iceberg fit, and why they’re already playing a prominent role in the future (and present) of data infrastructure. The majority of this post will be centered around the data lakehouse architecture. Data Lakes have been a staple for a long time, storing both structured and unstructured data. Over the last few years, the importance of data lakes has risen dramatically as their capabilities have evolved. The rise of foundation models and generative AI only furthers this trend. A key benefit of foundation models is their ability to add reason and logic on top of unstructured data. Data Lakehouses provide the crucial piece of infrastructure for foundation models to securely and efficiently access both structured and unstructured data with governance intelligently wrapped around it. But this isn’t another post about AI, it’s about the future of data infrastructure. However, the two are intertwined together. As Frank Slootman (Snowflake CEO) said, “Enterprises are also realizing that they cannot have an AI strategy without a data strategy to base it on.” Similarly, Satya Nadella (Microsoft CEO) said “Every AI app starts with data, and having a comprehensive data and analytics platform is more important than ever.” This post will dig into how the foundation layer of AI, data infrastructure, is evolving. Let's dive in.
Data lakes that turn into swamps
People describe data as the new oil but I think it’s more than that. Data is oxygen; it’s necessary for survival. Data is becoming the driving competitive force companies differentiate on. Data creates long-term moats and ultimately helps organizations deliver differentiated products to their end customers. How you acquire customers, which features you build, which promotions you run are all data-driven decisions that compound into long term advantages.
One key component of a modern cloud-native data architecture is the data lake - which allows for cost-efficient storage of large amounts of data used for analytics and ML at scale. Another key component is the data warehouse, which provides a central store of (typically) structured and transformed data ready for SQL queries.
I wrote a post about the data lake / data warehouse a few years back you can find here. One key graphic I’ll share from that post is below. This image is an oversimplified view of the two-tier lake / warehouse architecture. The data lake is optimized for cheap and scalable storage (but not retrieval) of all kinds of structured or unstructured data. Data sitting in a data lake is then extracted, loaded and transformed into a data warehouse. The warehouse is then optimized for efficient access (typically through SQL) to that data, with a number of other properties layered in (like governance, access, security, etc).

In this post, I’ll focus more on the data lake portion of the diagram above. Typical data lake storage solutions include AWS S3, Azure Data Lake Storage (ADLS), Google Cloud Storage (GCS) or Hadoop Distributed File System (HDFS).
A natural question is “why do we have two tiers? Why not have one central place where data is stored?” Well, the data lake comes with many challenges. At the end of the day it’s optimized for storage, not access (this is something I’ll refer to a lot).
There have been four big issues with data lakes - (1) you can’t perform ACID transactions, (2) you can’t write SQL against them, making it difficult to retrieve data (but Hive? Just terrible performance…), (3) there’s no real security / governance, and (4) data quality controls don’t exist. These 4 aren’t necessarily as absolute as I make it sound, but doing any of the 4 things above on a data lake is incredibly hard. Because of all of these issues, the data lake was really more of a data swamp. They were hard to use and messy.
I mentioned ACID transactions, so let’s unpack that. At a high level it’s one of the core properties of any production database, and it guarantees that database transactions are processed accurately and reliably. Here’s what the acronym stands for:
(A) Atomicity: This property ensures that a transaction is treated as a single, indivisible unit of work, meaning that either all the changes made in a transaction are committed to the database, or none of them are. If a transaction is interrupted (for example, by a power outage or system crash), any changes are rolled back, so the database remains unchanged.
(C) Consistency: This property ensures that a transaction brings a database from one valid state to another, maintaining the integrity constraints of the database. If a transaction would violate the database's consistency rules, it is rolled back and the database remains unchanged.
(I) Isolation: This property ensures that concurrent execution of transactions leaves the database in the same state as if the transactions were executed sequentially. This means that the intermediate state of a transaction is invisible to other transactions. As a result, transactions that run concurrently appear to be serialized.
(D) Durability: This property ensures that once a transaction has been committed, it will remain committed even in the case of a system failure (like a power outage or crash). This is typically achieved by storing committed transactions in a non-volatile memory.
In summary, ACID properties guarantee that if I ask a question of a database I get the right answer back, no matter what. This is important in large-scale production systems where you may have thousands of concurrent requests (both reads and writes), systems fail, yet ultimately the same answer must be given to one single question, no matter what.
Because of these data lake shortcomings, the cloud data warehouse was born. The data warehouse (Snowflake, AWS Redshift, Azure Synapse, Google BigQuery) provided ACID guarantees, let you write SQL to retrieve data, came with powerful query engines to optimize the retrieval of data, offered an engine to transform, manipulate and organize tables, and wrapped all of this inside tight security and governance policies.
From Data Swamp to Data Lakehouse
Over time, people have tried to merge these two worlds (the data warehouse and data lake) into what many now call a data lakehouse. Look no further than the Snowflake / Databricks debate for evidence of this! Both of these vendors want to provide a one stop shop for all of your data needs; Snowflake starts from a warehouse perspective and Databricks from that of a data lakehouse.
In truth, innovations in the past few years are helping evolve the data lake (swamp) into a data lakehouse! I’ll dig in more on this later on, but to summarize ahead of time the 4 main components of a data lakehouse are:
Data lake storage (object storage): S3, ADLS, GCS, HDFS. Data lake storage is typically managed in a folder / file structure
File Formats (Parquet, CSV, JSON, ORC, Avro etc): row or columnar based file formats (where actual data is stored)
Table formats (Iceberg, Delta, Hudi): these abstract the physical data structure complexity, and help compute engines efficiently access the data.
Compute engine (query engine): Performs the actual data retrieval. Crunches the data transformations and aggregations, and distributes the workloads.
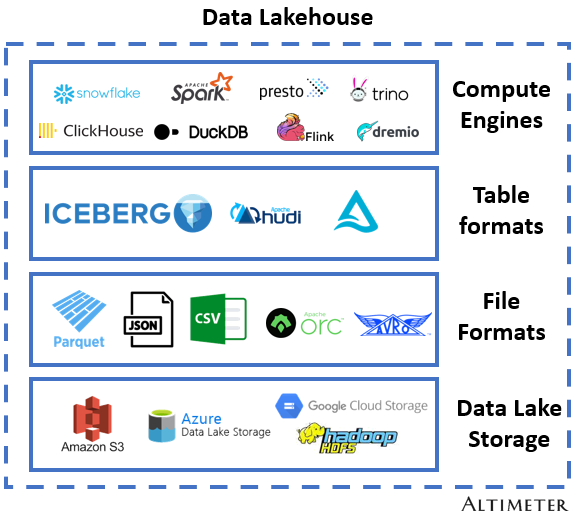
Data Lakehouse Components: Data lake Storage, File Formats, Table Formats, Compute Engines
On top of this (above the compute engines) we have applications that use data like BI tools or notebooks (Looker, Tableau, Hex, Sigma, Jupyter Notebooks, etc.)
One of the first popular data lake engines was Apache Hive (in the Hadoop era, designed for HDFS, not necessarily object stores like S3). As I described above, the data lake solutions (S3, ADLS, GCS, HDFS) were really just storage formats. The Hive engine gave us more efficient access patterns to data lake storage. It was file format-agnostic and could give a single answer to “what data is in this table.” However, there were MANY challenges that ultimately led to the end of the Hadoop / Hive era.
Smaller updates were incredibly inefficient (Hive updates entire partitions, so if you only want to change a few rows at a time there is a lot of needless reading).
There’s no way to change data in multiple partitions safely (if you want to insert a row into a certain partition it can’t guarantee it).
Hive was INCREDIBLY slow - it relies on the directory listing the partitions with huge complexity for query planning. To retrieve data you have to first go to the directory, read each file, retrieve the data, close the file, etc.
And maybe most importantly, there was no abstraction. Users have to know the physical layout of the table and name the partition in order to avoid full table scans (meaning it was really expensive and took a long time).
Note that Hive is a compute engine combined with a metastore that became a de facto catalog for the data lake. But, Hive does not provide a true table specification.
Apache Iceberg – the Table Specification for your Lakehouse
This is where Iceberg comes in. Iceberg is an open table format developed by Ryan Blue and Dan Weeks (2 of the 3 co-founders of Tabular) while they were at Netflix. The third Tabular founder is Jason Reid, Ryan and Dan’s internal customer as Director of Data Engineering. Netflix was facing many challenges (some described above) with their data lake, and Iceberg was created to solve a lot of the challenges of Hive (at Netflix scale).
Tabular provides a managed Iceberg and data lakehouse solution. There are still thousands of companies still using Hive. If you are one of them, and have any frustrations with it, I think you should chat more with Tabular :)
So what is a table format, and what is Iceberg? A table format is a way to organize data files (Parquet, JSON, etc) and present them as a single table. It’s an abstraction of file formats that can be presented to query engines (it’s difficult for query engines to direct questions directly at the data lake storage layer).
Iceberg uses metadata for the heavy lifting, as opposed to the directory listing like Hive. The metadata defines the table structure partitions and data files so you don’t need to query a directory (more on that architecture below). Iceberg is open source, and is the leading table format, having been adopted by Snowflake, AWS, GCP, Databricks, Confluent and many others, with contributions and usage coming from some of the largest organizations like Netflix, Apple, LinkedIn, Adobe, Salesforce, Stripe, Pinterest, AirBNB, Expedia and many others. The adoption of Iceberg across the data industry is accelerating and it’s clear it’s well on its way to becoming an industry staple. Here are just a few Iceberg announcements from major platforms:
Snowflake initial Iceberg support in 2022 (further deepened relationship in 2023)
How does Iceberg accomplish so much? The chart below is from the Iceberg spec.
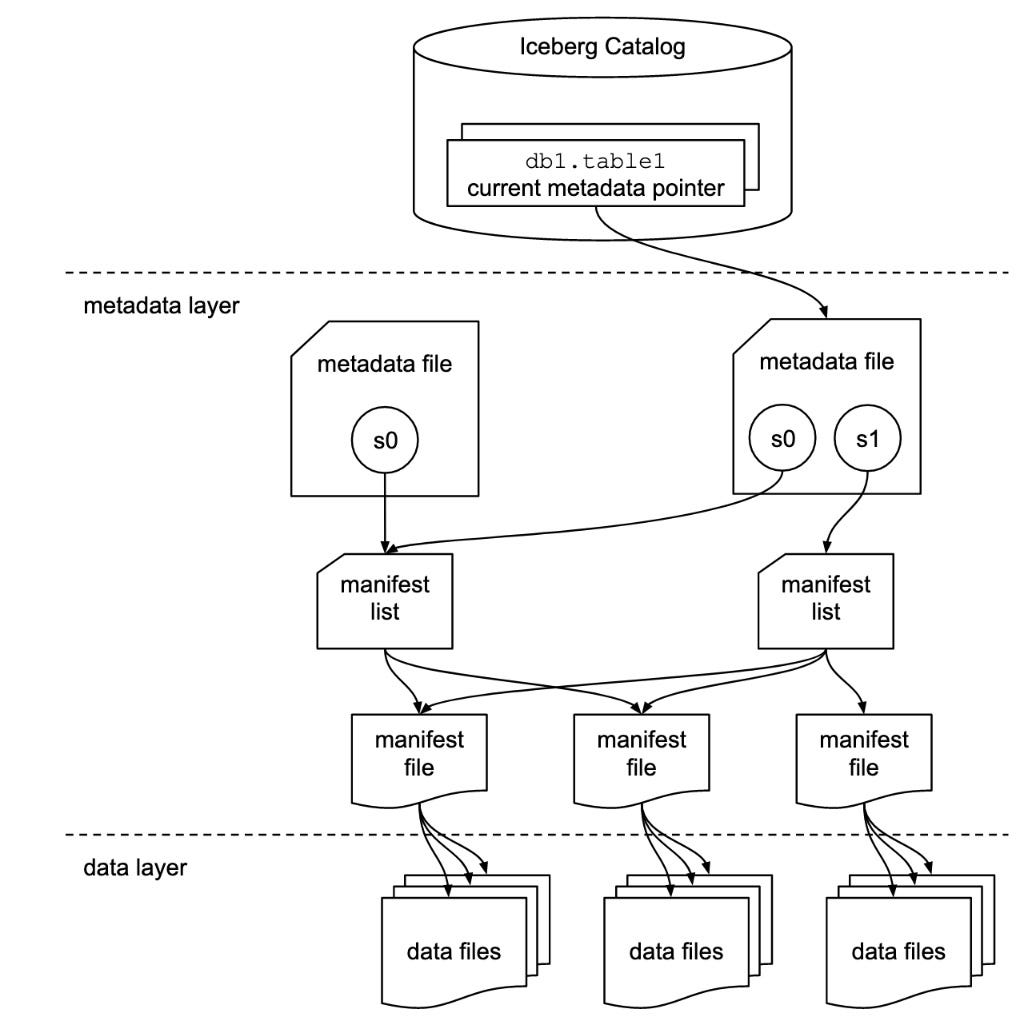
Source: https://iceberg.apache.org/spec/
I won’t go into the specifics of each layer (catalog, metadata, and data layers), but if you want more technical detail this post does a great job.
So what does Iceberg enable? What are the benefits of Iceberg and Tabular?
Portable Compute (zero-copy architecture): This is the most important feature of an Iceberg data lakehouse, and I’ll talk more about it coming up. Iceberg tables are interoperable with any compute engine. With Iceberg, you bring your compute to your data; you don’t copy data all around and create a governance nightmare. Use Snowflake for analytics reporting, Flink for stream processing, Spark for data processing, etc. Iceberg lets you store the data in one place, and use whatever query engine is best for that specific workload.
Expressive SQL: Another super important feature. One of the core data warehouse primitives we’ve come to rely on is SQL - data users know and love SQL, and want to write SQL to access data. Iceberg brings SQL compatibility to the data lake world. This is HUGE. With Iceberg you can perform row-level declarative SQL commands like row level merge, update and deletes. This is exactly how you work with data in a data warehouse, and was not possible before Iceberg. Iceberg brings the power of data warehouses to the data lake space
Time Travel and Rollback: The Iceberg metadata model is a “share nothing” model. In a share nothing model, everything is stored in S3 or other object storage. You do need multiple snapshots of your data which may seem wasteful, however this allows for time travel and roll-backs. Iceberg leaned into the git functionality that software developers have become accustomed to.
With Iceberg and its share nothing architecture you can do branching and tagging. When you’re running merge commands or you’re testing changes to the merge commands you can do that in a branch of the data. You can test, validate and then push a branch to production. Tagging is also quite cool - you can tag a table used for quarterly reports or training an AI model so you can refer back to it. Ultimately, every change to an Iceberg table is a snapshot.
Schema Evolution: Iceberg greatly reduces the impact of inevitable schema changes. Change schema all you want! You won’t need to rewrite entire tables when you change the schema. This is a game changer for efficiency, and allows organizations to be more nimble with their data.
Data Compaction and Storage Cost Reduction: More self explanatory, but the amount of redundant data sitting in S3 is mind blowing. We talked with Iceberg / Tabular users who are saving millions on their S3 costs just with the Iceberg / Tabular data compaction. This article talks about how Insider cut their S3 costs by 90% with Iceberg. Reducing storage can also reduce compute costs by having queries run faster (fewer credits burned) or less data scanned (e.g. for Athena which charges in the manner)
Audits and Data Quality: Iceberg brings a lot of software engineering best practices to data engineering. In addition to merge workflows, you can integrate audits in Iceberg workflows. When you commit to an Iceberg table you can audit the results, then fast forward the main branch to what you’ve audited. This prevents bad data from leaking downstream. You probably hear about the danger of poor data quality a lot. With audits in your workflow you don’t have to fix 20 downstream tables when a data issue emerges.
Performance: Iceberg provides automatic pruning, column level filtering, indexed metadata – all of which leads to faster query execution
When Ryan and team initially set out to create Iceberg the goal was to bring the capabilities of a data warehouse to a data lake, thus creating a data lakehouse. What they discovered, and what Iceberg / Tabular has turned into, is an entirely new paradigm. We’ve seen the number of compute engines explode. And these engines have vastly different architectures or paradigms (JVM vs Python, Batch vs Streaming, etc). This has led to an intricate and complex web of data platforms that large enterprises manage.
Databricks and Snowflake pitch a single place for everything, but the reality is Spark is great for some use cases, Snowflake for others, Flink for streaming, DuckDB or Clickhouse for faster real time systems, etc.
Further, each engine maintains their own security, governance and access policies!
Tabular - an Independent Data Platform from the Creators of Apache Iceberg
Ten years ago Snowflake did something very innovative - they separated storage and compute, and scaled each independently. Since then, as I described above, the number of compute engines has exploded. This has resulted in data stored in S3, then replicated to a number of other systems, all of which manage their own governance and security. What a headache!
Enter Tabular - Tabular is creating a new data lakehouse architecture that even further separates storage and compute by allowing you to use services from different vendors for storage (including table management) and compute. With Tabular, you have one source of truth for your storage: your data lakehouse (i.e. Tabular). Then, compute engines are mixed and matched on top based on your use cases.
This provides a very important data security advantage. Because Tabular provides RBAC on storage - down to the table level, and soon to the column, you define security and governance policies at the lowest level once, and they get enforced across your compute engines automatically.
To recap, with Tabular you store once and use anywhere. You define and create a Tabular catalog once that acts as a single source of truth for data discovery and access. Data compaction makes the storage efficient. You then have separate compute and query engines (Snowflake, Spark, Flink, Trino, etc) that you bring to this data (ie bringing compute to the data). You store the data once, and use it anywhere (use it with any engine).
If you’re a large enterprise, you don’t have to pick between Databricks and Snowflake - you can have both with unified security and governance! On top of this, you can completely avoid vendor lock-in to either one of these platforms (as the data gravity moves away from the compute providers themselves). Further separating storage and compute into separate vendors truly enables a best of breed architecture, creating a unified data architecture. Tabular makes the data storage layer universal. Anyone doing any task can share their data without copying, syncing or worrying about permissions. You govern the entire data layer itself in one place.
Avoid Compute Lock-In!
No one wants to get “Oracle-d.” However, as some of the more modern platforms today push a one-stop shop all-you-can-eat data platform, the risk of lock-in is higher. Especially at the compute layer, where customer costs / vendor revenues are soaring.
And while Iceberg provides an open table spec, each vendor of an Iceberg managed service who also sells a compute layer has a vested interest in providing a performance advantage to their engine. Therefore, you can still end up with a form of lockin.
With Tabular these fears go away. You store your data once, and then are free to use the best compute engine for each workload (ie portable compute, point #1 above) and since Tabular doesn’t have a horse in the compute engine race, it’s in their best interests to treat them all the same way.

This is the cloud-native data architecture of the future, and why we’re so excited to partner with Ryan and the Tabular team. Bringing the flexibility of the data warehouse to the scalability of the data lake is incredibly powerful. The ability to safely use multiple engines that don’t know anything about one another on the same data sets at the same time (whether it’s a Python process someone is running in Hex, or a Snowflake job, or a Spark job, etc) is incredibly powerful. And for most enterprises, they’re already using all of these compute engines. We see a world in the future where best of breed storage and compute vendors are further separated. Providing SQL warehouse behavior on the data lake with strong guarantees makes people and companies more productive with their data. Having a cloud-native data strategy will differentiate companies over the next decade, and I highly encourage everyone to reach out to the Tabular team to learn how their solution can truly up level your data strategy.
With Tabular, I believe you can turn your data swamp into a data lakehouse.
Great article. Quick question, when Slootman and Nadella talk about of importance with data in AI, how does structured data play into it? Since most ML models are using unstructured data for training, are warehouses only used to store the outputs the model comes up with, or are we going to have models that are trained on unstructured data then given structured to come up with business insights?
Good to see the continued growth and investment in this sector. Early days for sure, but this will be the default for how data is architected: data lakes, open formats, tabular formats and a choice of SQL engines.